Understanding Camunda 7 transaction handling
This best practice targets Camunda 7.x only! Zeebe, the workflow engine used in Camunda 8, as a very different transactional behavior, please visit dealing with problems and exceptions.
Try to carefully study and fully understand the concepts of wait states (save points) acting as transaction boundaries for technical (ACID) transactions. In case of technical failures, they are by default rolled back and need to be retried either by the user or the background job executor.
Understanding technical (ACID) transactions in Camunda 7
Every time we use the Camunda 7 API to ask the workflow engine to do something (like e.g. starting a process, completing a task, signaling an execution), the engine will advance in the process until it reaches wait states on each active path of execution, which can be:
1User tasks and receive tasks
2All intermediate catching events
3The event based gateway, which offers the possibility of reacting to one of multiple intermediate catching events
4Several further task types (service, send, business rule tasks)
5External Tasks are wait states, too. In this case, the throwing message events might be implemented as external task.
At a wait state, any further process execution must wait for some trigger. Wait states will therefore always be persisted to the database. The design of the workflow engine is, that within a single database transaction, the process engine will cover the distance from one persisted wait states to the next. However, you have fine grained control over these transaction boundaries by introducing additional save points using the async before and async after attributes. A background job executor will then make sure that the process continues asynchronously.
Learn more about transactions in processes in general and asynchronous continuations in the user guide.
Sometimes when we refer to "transactions" in processes, we refer to a very different concept, which must be clearly distinguished from technical database transactions. A business transaction marks a section in a process for which 'all or nothing' semantics apply, but from a pure business perspective. This is described in dealing with problems and exceptions.
Controlling transaction boundaries
Using additional save points
You have fine grained control over transaction boundaries by introducing save points additionally to wait states, that are always a save point. Use the asyncBefore='true' and asyncAfter='true' attributes in your process definition BPMN XML. The process state will then be persisted at these points and a background job executor will make sure that it is continued asynchronously.
A user task is an obligatory wait state for the process engine. After the creation of the user task, the process state will be persisted and committed to the database. The engine will wait for user interaction.
2This service task is executed "synchronously" (by default), in other words within the same thread and the same database transaction with which a user attempts to complete the "Write tweet" user task. When we assume that this service fails in cases in which the language used is deemed to be too explicit, the database transaction rolls back and the user task will therefore remain uncompleted. The user must re-attempt, e.g. by correcting the tweet.
3This service task is executed "asynchronously". By setting the asyncBefore='true' attribute we introduce an additional save point at which the process state will be persisted and committed to the database. A separate job executor thread will continue the process asynchronously by using a separate database transaction. In case this transaction fails the service task will be retried and eventually marked as failed - in order to be dealt with by a human operator.
Pay special attention to the consequence of these save points with regards to retrying. A retry for a job may be required if there are any failures during the transaction which follows the save point represented by the job. Depending on your subsequent transaction boundaries this may very well be much more than just the service task which you configured to be asyncBefore='true'! The process instance will always roll back to its last known save point, as discussed later.
Marking every service task as asynchronous
A typical rule of thumb, especially when doing a lot of service orchestration, is to mark every service task being asynchronous.
The downside is that the jobs slightly increase the overall resource consumption. But this is often worth it, as it has a couple of advantages for operations:
- The process stops at the service task causing the specific error.
- You can configure a meaningful retry strategy for every service task.
- You can leverage the suspension features for service tasks.
While it is not directly configurable to change Camunda 7's default "async" behavior for all service tasks at once, you can achieve that by implementing a custom ProcessEnginePlugin introducing a BpmnParseListener which adds async flags on-the-fly (eventually combined with custom BPMN extension attributes to control this behavior). You can find a code example for a similar scenario on GitHub.
Knowing typical do's and don'ts for save points
Aside a general strategy to mark service tasks as being save points you will often want to configure typical save points.
Do configure a savepoint after
User tasks
 : This savepoint allows users to complete their tasks without waiting for expensive subsequent steps and without seeing an unexpected rollback of their user transaction to the waitstate before the user task. Sometimes, e.g. when validating user input by means of a subsequent step, you want exactly that: rolling back the user transaction to the user task waitstate. In that case you might want to introduce a savepoint right after the validation step.
: This savepoint allows users to complete their tasks without waiting for expensive subsequent steps and without seeing an unexpected rollback of their user transaction to the waitstate before the user task. Sometimes, e.g. when validating user input by means of a subsequent step, you want exactly that: rolling back the user transaction to the user task waitstate. In that case you might want to introduce a savepoint right after the validation step.Service Tasks (or other steps) causing Non-idempotent Side Effects




 : This savepoint makes sure that a side effect which must not happen more often than once is not accidentally repeated because any subsequent steps might roll back the transaction to a savepoint well before the affected step. End Events should be included if the process can be called from other processes.
: This savepoint makes sure that a side effect which must not happen more often than once is not accidentally repeated because any subsequent steps might roll back the transaction to a savepoint well before the affected step. End Events should be included if the process can be called from other processes.Service tasks (or other steps) executing expensive Ccmputations
: This savepoint makes sure that a computationally expensive step does not have to be repeated just because any subsequent steps might roll back the transaction to a savepoint well before the affected step. End Events should be included if the process can be called from other processes.Receive tasks (or other steps) catching external events, possibly with payload


 : This savepoint makes sure that a external event like a message is persisted as soon as possible. It cannot get lost just because any subsequent steps might roll back the transaction to a savepoint well before the affected step. This applies also to External Service Tasks.
: This savepoint makes sure that a external event like a message is persisted as soon as possible. It cannot get lost just because any subsequent steps might roll back the transaction to a savepoint well before the affected step. This applies also to External Service Tasks.
Do configure a savepoint before
Start events



 : This savepoint allows to immediately return a process instance object to the user thread creating it - well before anything happens in the process instance.
: This savepoint allows to immediately return a process instance object to the user thread creating it - well before anything happens in the process instance.Service tasks (or other steps) invoking remote systems
: This savepoint makes sure that you always transactionally separate the potentially more often failing remote calls from anything that happens before such a step. If a service call fails you will observe the process instance waiting in the corresponding service task in cockpit.Parallel joins


 : Parallel joins synchronize separate process pathes, which is why one of two path executions arriving at a parallel join at the same time will be rolled back with an optimistic locking exception and must be retryed later on. Therefore such a savepoint makes sure that the path synchronisation will be taken care of by Camunda's internal job executor. Note that for multi instance activities, there exists a dedicated "multi instance asynchronous after" flag which saves every single instance of those multiple instances directly after their execution, hence still "before" their technical synchronization.
: Parallel joins synchronize separate process pathes, which is why one of two path executions arriving at a parallel join at the same time will be rolled back with an optimistic locking exception and must be retryed later on. Therefore such a savepoint makes sure that the path synchronisation will be taken care of by Camunda's internal job executor. Note that for multi instance activities, there exists a dedicated "multi instance asynchronous after" flag which saves every single instance of those multiple instances directly after their execution, hence still "before" their technical synchronization.
The Camunda JobExecutor works (by default) with exclusive jobs, meaning that just one exclusive job per process instance may be executed at once. Hence, job executor threads will by default not cause optimistic locking exceptions at parallel joins "just by themselves", but other threads using the Camunda API might cause them - either for themselves or also for the job executor.
Don't configure save points before
User tasks and other wait states

 including steps configured as external tasks : Such savepoints just introduce overhead as wait-states on itself finish the transaction and wait for external intervention anyway.
including steps configured as external tasks : Such savepoints just introduce overhead as wait-states on itself finish the transaction and wait for external intervention anyway.All forking and exclusively joining gateways
 : There should just be no need to do that, unless execution listeners are configured at such points, which could fail and might need to be transactionally separated from other parts of the execution.
: There should just be no need to do that, unless execution listeners are configured at such points, which could fail and might need to be transactionally separated from other parts of the execution.
Adding save points automatically to every model
If you agree on certain save points to be important in all your process definitions, you can add required BPMN XML attributes automatically by a Process Engine Plugin during deployment. Then you don't have to add this configuration to each and every process definition yourself.
As a weaker alternative the plugin could check for existance of correct configuration and log warnings or errors if save points are missing.
Take a look at this example for details.
Thinking about operations during modeling
Make sure you also understand how to operate Camunda 7 - in particular by understanding retry behaviour and incident management for service tasks.
Rolling back a transaction on unhandled errors
It is important to understand that every non-handled, propagated exception happening during process execution rolls back the current technical transaction. Therefore the process instance will find its last known wait state (or save point). The following image visualizes that default behavior.
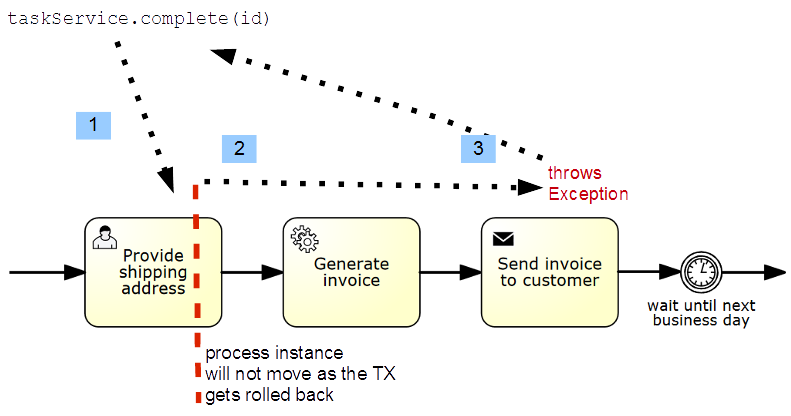
When we ask the Camunda engine to complete a task ...
2... it tries to advance the process within the borders of a technical transaction until it reaches wait states (or save points) again.
3However, in cases where a non-handled exception occurs on the way, this transaction is rolled back and we find the user task we tried to complete to be still uncompleted.
From the perspective of a user trying to complete the task, it appears impossible to complete the task, because a subsequent service throws an exception. This can be unfortunate, and so you very well may want to introduce additional save points, e.g. here before the send task.
<sendTask id="send" name="Send invoice to customer" camunda:asyncBefore="true" camunda:class="my.SendDelegate" />
But hindering the user to complete the user task can also be just what you want. Consider e.g. the possibility to validate task form input via a subsequent service:
1A user needs to provide data with a user task form. When trying to complete the form ...
2... the subsequent synchronously executed service task finds a validation problem and throws an exception which rolls back the transaction and leaves the user task uncompleted.
Learn more about rollback on exceptions and the reasoning for this design in the User Guide.
Handling exceptions via the process
As an alternative to rolling back transactions, you can also handle those exceptions within the process, refer to dealing with problems and exceptions for details.
Just be aware of the following technical constraint: in case your transaction manager marks the current transaction for rollback (as possible in Java transaction managers), handling the exception by a processis not possible as the workflow engine cannot commit its work in this transaction.