Dual-region
Camunda 8 can be deployed in a dual-region configuration with certain limitations. This setup combines active-active data replication with active-passive user traffic routing (see Active-active) to ensure high availability and disaster recovery.
Both regions must be fully operational at all times. The only distinction is traffic routing: one region serves user traffic (primary), the other processes data but doesn't serve user traffic (secondary).
Before implementing a dual-region setup, ensure you understand the topic, the limitations of dual-region setup, and the general considerations of operating a dual-region setup.
Architecture overview
The dual-region setup is a hybrid active-active/active-passive architecture:
| Component | Mode | Both Regions Running | User Traffic | RPO |
|---|---|---|---|---|
Orchestration Cluster | ✅ Required | |||
| Zeebe | Active-active | ✅ Required | Both regions process data | 0 |
| Identity | Active-active | ✅ Required | Cluster-level identity | 0 |
| Operate | Active-passive (see Active-active) | ✅ Required | One region serves users | 0 |
| Tasklist | Active-passive (see Active-active) | ✅ Required | One region serves users | 0 |
Elasticsearch | Active-active | ✅ Required | Data replicated to both | 0 |
All components in both regions must be fully operational at all times. "Passive" refers only to user traffic routing, not system operation. Both regions actively participate in data processing and replication.
Traffic routing and terminology
Primary and secondary regions
To avoid confusion with traditional "active-passive" terminology, we distinguish between:
- Primary region: Serves user traffic (UI access, API calls).
- Secondary region: Fully operational but does not serve user traffic under normal conditions.
Both regions are operationally active with all components running, but only the primary region handles user interactions.
User traffic management
You must route user traffic exclusively to the primary region (*). Methods include:
- DNS configuration
- Load balancer settings
- Network routing policies
If the primary region fails, traffic must be redirected manually to the secondary region.
Active-active vs active-passive comparison
-
Active-active setups distribute user traffic across multiple regions simultaneously, with all regions processing requests.
-
Active-passive setups designate one region for user traffic while keeping backup regions on standby.
-
Camunda's hybrid approach combines both:
- Data layer: Active-active replication ensures zero data loss (RPO = 0).
- User interface layer: Active-passive routing prevents conflicts and ensures consistency.
Disclaimer
Running dual-region setups requires developing, testing, and executing custom operational procedures matching your environments. This page outlines key points to consider.
Starting in Camunda 8.8, the v2 REST API and Tasklist V2 remove previous region-specific limitations. By using the v2 REST API for batch operations and enabling Tasklist V2 mode, you can avoid regional data loss, as data is replicated through the Camunda Exporter rather than confined to the region where the operation originated.
These improvements also make a user-facing active-active setup feasible. Starting with version 8.9, this configuration will become the default for dual-region deployments. This note serves as an early indication that active-active functionality is already supported.
Dual-region architecture
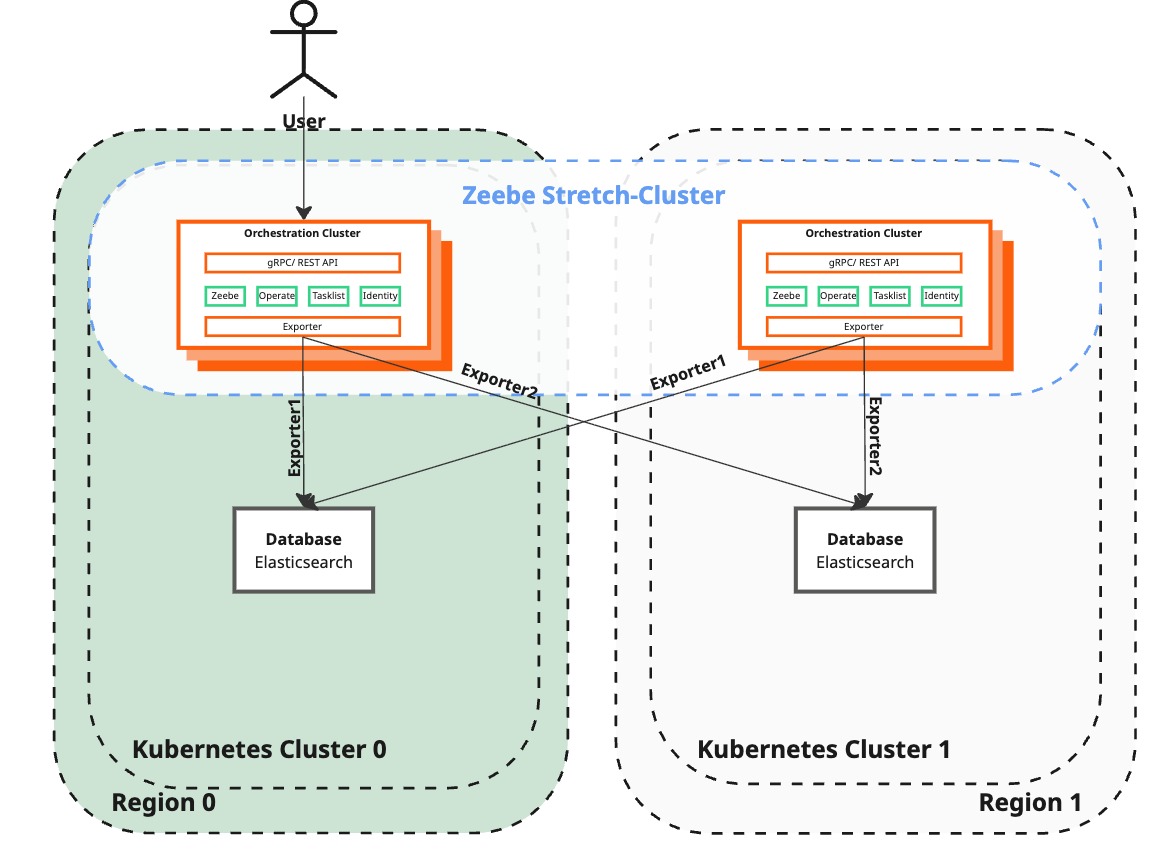
The dual-region architecture consists of two regions in a Kubernetes-based installation. Each region has a Kubernetes cluster with all Camunda 8 components fully operational.
- Region 0 is the primary region serving user traffic.
- Region 1 is the secondary region, fully operational but not serving user traffic.
Both regions actively participate in data processing and replication.
The visual representation shows both regions as operational. Any grayed-out appearance in the diagram represents user traffic routing, not system operational status. All components in both regions must be running and operational.
The Orchestration Cluster consists of multiple components:
- Zeebe stretches across regions using the Raft protocol, allowing communication and data replication between all brokers.
- Zeebe exports data to Elasticsearch instances in both regions using the Camunda Exporter.
- Using the new exporters ensures that Operate and Tasklist data is the same in both regions besides some v1 API related operations that are still region specific. See active-active.
- Identity is embedded in the Orchestration Cluster and provides cluster-level identity management.
User traffic
The system uses active-passive user traffic routing. You must designate one region as the primary and route all user traffic to it. The secondary region remains fully operational but does not serve user requests (see Active-active).
Traffic management responsibilities:
- Configure DNS to route to primary region.
- Implement health checks and failover procedures.
- Manually redirect traffic during primary region failure in combination with the operational failover procedure.
Traffic redirection must be performed as part of the complete failover procedure. Redirecting traffic without following the operational procedure can lead to system inconsistencies and data issues.
Components
The currently supported Camunda 8 Self-Managed components are:
- Orchestration Cluster
- Zeebe (process automation engine)
- Identity
- Operate
- Tasklist
- Elasticsearch (database)
Component requirements
| Component | Mode | Requirement | Function | Data loss risk |
|---|---|---|---|---|
Orchestration Cluster | ||||
| Zeebe | Active-active | All brokers in both regions must run |
| Can handle region failure without data loss when properly configured |
| Identity | Active-active | Embedded in the Orchestration cluster |
| Can handle region failure without data loss |
| Operate | Active-passive (user traffic) (see Active-active) | Embedded in the Orchestration cluster |
| Data loss possible if using v1 API as changes are isolated to the initiated region. |
| Tasklist | Active-passive (user traffic) (see Active-active) | Embedded in the Orchestration cluster |
| Data loss possible if using v1 API as changes are isolated to the initiated region. |
Elasticsearch | Active-active | Both clusters must run |
| Zeebe exporters may fail globally if secondary ES is down |
Requirements and limitations
Installation environment
Two Kubernetes clusters are required for the Helm chart installation.
Amazon OpenSearch is not supported in dual-region configurations.
Network requirements
- Kubernetes clusters, services, and pods must not have overlapping CIDRs. Each cluster must use distinct CIDRs that do not conflict or overlap with those of any other cluster to avoid routing issues.
- The regions (for example, two Kubernetes clusters) must be able to communicate with each other (for example, via VPC peering). See example implementation for AWS EKS.
- Kubernetes services in one cluster must be resolvable and reachable from the other cluster and vice-versa. This is essential for proper communication and functionality across regions:
- For AWS EKS setups, ensure DNS chaining is configured. Refer to the Amazon Elastic Kubernetes Service (EKS) setup guide.
- For OpenShift, Submariner is recommended for handling multi-cluster networking. Refer to the OpenShift dual-region setup guide.
- Kubernetes services in one cluster must be resolvable and reachable from the other cluster and vice-versa. This is essential for proper communication and functionality across regions:
- Maximum network round trip time (RTT) between regions should not exceed 100 ms.
- Required open ports between the two regions:
- 9200 for Elasticsearch (for cross-region data pushed by Zeebe).
- 26500 for communication to the Zeebe Gateway from clients/workers.
- 26501 and 26502 for communication between Zeebe brokers and the Zeebe Gateway.
Zeebe cluster configuration
The following Zeebe brokers and replication configuration are supported:
clusterSizemust be a multiple of 2 and at least 4 to evenly distribute brokers across the two regions.replicationFactormust be 4 to ensure even partition distribution across regions.partitionCountis unrestricted but should be chosen based on workload requirements. See understanding sizing and scalability behavior. For more details on partition distribution, see documentation on partitions.
Zeebe creates partitions in a round-robin fashion. The Helm charts ensures that all brokers with even numbers (0, 2, 4, 6, ...) are created in the same region. The brokers with uneven numbers (1, 3, 5, 7, ...) are created in the other region.
This numbering and the round-robin partition distribution assures the even replication across the two regions.
Scaling Zeebe cluster
Follow the Cluster Scaling steps respecting the Zeebe cluster configuration.
- The cluster should be evenly scaled, keeping the regions balanced with the same number of brokers.
Camunda 8 dual-region limitations
| Aspect | Details |
|---|---|
| Installation methods |
|
| Traffic Management | Hybrid active-active/active-passive architecture:
|
| Management Identity Support | Management Identity, including multi-tenancy and role-based access control (RBAC), is currently unavailable in this setup. Multi-tenancy and RBAC are supported using the Orchestration Cluster level Identity. |
| Optimize Support | Not supported (requires Management Identity with specific configuration). |
| Connectors Deployment | Connectors can be deployed in a dual-region setup, but attention to idempotency is required to avoid event duplication. In a dual-region setup, you'll have two connector deployments, so using message idempotency is critical. |
| Connectors | If you are running Connectors and have a process with an inbound connector deployed in a dual-region setup, consider the following:
|
| Zeebe Cluster Scaling | Supported. See Zeebe cluster configuration |
| Web Modeler | Web Modeler is a standalone component that is not covered in this guide. Modelling applications can operate independently outside of the orchestration clusters. Web Modeler also has a dependency on Management Identity. |
Infrastructure and deployment platform considerations
Multi-region setups come with inherent complexities, and it is essential to fully understand these challenges before selecting a dual-region configuration.
The following areas must be managed independently, and are not controlled by Camunda or covered by our guides:
- Kubernetes cluster management: Managing multiple Kubernetes clusters and their deployments across regions
- Monitoring and alerting: Dual-region monitoring and alerting with cross-region correlation
- Cost implications: Increased costs of multiple clusters and cross-region traffic
- Network reliability: Data consistency and synchronization challenges (for example, brought in by the increased latency)
- Bursts of increased latency can already have an impact
- Traffic management: Managing DNS and incoming traffic routing
- Security: Ensuring consistent security policies and network controls across regions
- Backup and disaster recovery: Coordinating backup strategies across regions
Before implementing dual-region, ensure your organization has:
- Experience managing multi-cluster Kubernetes environments
- Established procedures for cross-region networking and security
- Monitoring and alerting systems capable of cross-region correlation
- Defined RTO/RPO requirements and tested recovery procedures
Upgrade considerations
Follow the upgrade recommendations provided in the Camunda Helm chart and the component-specific upgrade guides.
The general procedure outlined in the upgrade overview also applies. Before starting, always create a Camunda-supported backup.
For dual-region setups, use a staged upgrade approach: upgrade one region at a time. Upgrading both regions simultaneously can cause a loss of quorum in Zeebe partitions if brokers in both regions are upgraded at once. To prevent this, complete the upgrade in one region before proceeding with the other, ensuring that only one Zeebe broker is updated during each phase.
However, for certain minor version upgrades, simultaneous upgrades of both regions may be required to complete migration steps successfully. Always consult the release notes and migration instructions for your specific version before proceeding.
Region loss
In a dual-region setup, loss of either region affects Camunda 8's processing capability due to quorum requirements.
When a region becomes unavailable, the Zeebe cluster loses quorum (half of brokers unreachable) and immediately stops processing new data. This affects all components as they cannot update or process new processes until the failover procedure completes.
Region failure results in immediate service interruption:
- No new process instances can start
- Running process instances are suspended
- User interfaces become unavailable if primary region is lost
See the operational procedure for recovery steps from region loss and re-establishment procedures.
You must monitor for region failures and execute the necessary operational procedures to ensure smooth recovery and failover.
Primary region loss
If the primary region is lost:
- Service disruption: User traffic is unavailable
- Zeebe halt: Processing stops due to quorum loss
- Data loss: Region-specific data such as batch operations and task assignments is lost (see Active-active)
Recovery steps for primary region loss
- Temporary recovery: Follow the operational procedure for temporary recovery to restore functionality and unblock the process automation engine (zeebe).
- Traffic rerouting: Redirect user traffic to the secondary region (now primary).
- Data and task management:
- Reassign uncompleted tasks lost from the previous primary region.
- Recreate batch operations in Operate.
- Permanent region setup: Follow the operational procedure to create a new secondary region.
Secondary region loss
If the secondary region is lost:
- Zeebe halt: Processing stops due to quorum loss.
- No user impact: Traffic continues to be served by the primary region during recovery.
Recovery steps for secondary region loss
- Temporary recovery: Follow the operational procedure to temporarily recover and restore processing.
- Permanent region setup: Follow the operational procedure to create a new secondary region.
Unlike primary region loss, no user-facing data is lost and no traffic rerouting is necessary.
Disaster recovery
Based on all the limitations and requirements outlined in this article, you can consider the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) in case of a disaster recovery to help with the risk assessment.
The RPO is the maximum tolerable data loss measured in time.
The RTO is the time to restore services to a functional state.
For Operate, Tasklist, and Zeebe, the RPO is 0.
The RTO can be considered for the failover and failback procedures, both of which result in a functional state.
- failover has an RTO of < 1 minute to restore a functional state, excluding DNS reconfiguration and Networking considerations.
- failback has an RTO of 5 + X minutes to restore a functional state, where X is the time it takes to back up and restore Elasticsearch. This timing is highly dependent on the setup and chosen Elasticsearch backup type.
During our automated tests, the reinstallation and reconfiguration of Camunda 8 takes 5 minutes. This can serve as a general guideline for the time required, though your experience may vary depending on your available resources and familiarity with the operational procedure.
The Recovery Time Objective (RTO) estimates are based on our internal tests and should be considered approximate. Actual times may vary depending on the specific manual steps and conditions during the recovery process.
Further resources
- Familiarize yourself with our Amazon Elastic Kubernetes Service (EKS) setup guide. This showcases an example blueprint setup in AWS that utilizes the managed EKS and VPC peering for a dual-region setup with Terraform.
- The concepts in the guide are mainly cloud-agnostic, and the guide can be adopted by other cloud providers.
- Familiarize yourself with the operational procedure to understand how to proceed in the case of a total region loss and how to prepare yourself to ensure smooth operations.