Metrics
When operating a distributed system like Zeebe, it is important to put proper monitoring in place.
To facilitate this, Zeebe exposes an extensive set of metrics.
Zeebe exposes metrics over an embedded HTTP server.
Types of metrics
- Counters: A time series that records a growing count of some unit. Examples: number of bytes transmitted over the network, number of process instances started.
- Gauges: A time series that records the current size of some unit. Examples: number of currently open client connections, current number of partitions.
Metrics format
Zeebe exposes metrics directly in Prometheus text format. Read details of the format in the Prometheus documentation.
Example:
# HELP zeebe_stream_processor_records_total Number of events processed by stream processor
# TYPE zeebe_stream_processor_records_total counter
zeebe_stream_processor_records_total{action="written",partition="1",} 20320.0
zeebe_stream_processor_records_total{action="processed",partition="1",} 20320.0
zeebe_stream_processor_records_total{action="skipped",partition="1",} 2153.0
Configuring metrics
Configure the HTTP server to export the metrics in the configuration file.
Connecting Prometheus
As explained, Zeebe exposes the metrics over an HTTP server. The default port is 9600.
Add the following entry to your prometheus.yml:
- job_name: zeebe
scrape_interval: 15s
metrics_path: /actuator/prometheus
scheme: http
static_configs:
- targets:
- localhost: 9600
Available metrics
All Zeebe-related metrics have a zeebe_-prefix.
Most metrics have the following common label:
partition: Cluster-unique id of the partition
Both brokers and gateways expose their respective metrics. The brokers have an optional metrics exporter that can be enabled for maximum insight.
Metrics related to process processing:
zeebe_stream_processor_records_total: The number of events processed by the stream processor. Theactionlabel separates processed, skipped, and written events.zeebe_exporter_events_total: The number of events processed by the exporter processor. Theactionlabel separates exported and skipped events.zeebe_element_instance_events_total: The number of occurred process element instance events. Theactionlabel separates the number of activated, completed, and terminated elements. Thetypelabel separates different BPMN element types.zeebe_job_events_total: The number of job events. Theactionlabel separates the number of created, activated, timed out, completed, failed, and canceled jobs.zeebe_incident_events_total: The number of incident events. Theactionlabel separates the number of created and resolved incident events.zeebe_pending_incidents_total: The number of currently pending incident, i.e. not resolved.
Metrics related to performance:
Zeebe has a backpressure mechanism by which it rejects requests when it receives more requests than it can handle without incurring high processing latency.
Monitor backpressure and processing latency of the commands using the following metrics:
zeebe_dropped_request_count_total: The number of user requests rejected by the broker due to backpressure.zeebe_backpressure_requests_limit: The limit for the number of inflight requests used for backpressure.zeebe_stream_processor_latency_bucket: The processing latency for commands and event.
Metrics related to health:
The health of partitions in a broker can be monitored by the metric zeebe_health.
Grafana
Zeebe comes with a pre-built dashboard, available in the repository: monitor/grafana/zeebe.json.
Import it into your Grafana instance and select the correct Prometheus data source (important if you have more than one). You will then be greeted with the following dashboard, which displays a healthy cluster topology, general throughput metrics, handled requests, exported events per second, disk and memory usage, and more.
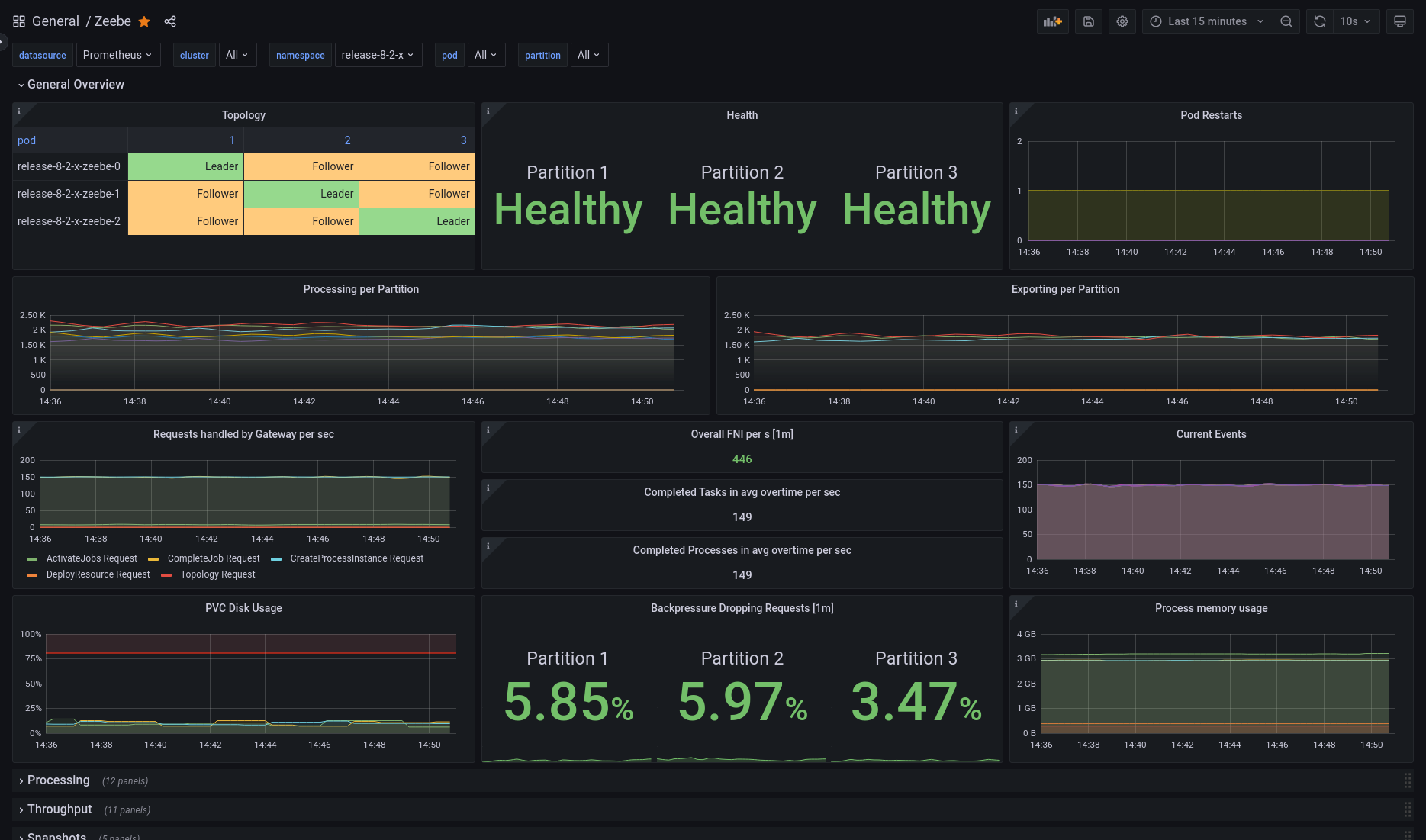
You can also try out an interactive version, where you can explore help messages for every panel and get a feel for what data is available.