Dual-region setup (EKS)
Review our dual-region concept documentation before continuing to understand the current limitations and restrictions of this blueprint setup.
This guide offers a detailed blueprint tutorial for deploying two Amazon Web Services (AWS) Elastic Kubernetes Service (EKS) clusters, tailored explicitly for deploying Camunda 8 and using Terraform, a popular Infrastructure as Code (IaC) tool.
This guide requires you to have previously completed or reviewed the steps taken in deploying an EKS cluster with Terraform. If you have no experience with Terraform and Amazon EKS, review this content for the essentials of setting up an Amazon EKS cluster and configuring AWS IAM permissions. This content explains the process of using Terraform with AWS, making it accessible even to those new to Terraform or IaC concepts.
Prerequisites
- An AWS account to create resources within AWS.
- Helm for installing and upgrading the Camunda Helm chart.
- Kubectl to interact with the cluster.
- Terraform
For the tool versions used, check the .tool-versions file in the repository. It contains an up-to-date list of versions that we also use for testing.
Considerations
This setup provides an essential foundation for setting up Camunda 8 in a dual-region setup. Though it's not tailored for optimal performance, it's a good initial step for preparing a production environment by incorporating IaC tooling.
To try out Camunda 8 or develop against it, consider signing up for our SaaS offering. If you already have two Amazon EKS clusters (peered together) and an S3 bucket, consider skipping to deploy Camunda 8 to the clusters.
For the simplicity of this guide, certain best practices will be provided with links to additional resources, enabling you to explore the topic in more detail.
Following this guide will incur costs on your Cloud provider account, namely for the managed Kubernetes service, running Kubernetes nodes in EC2, Elastic Block Storage (EBS), traffic between regions, and S3. More information can be found on AWS and their pricing calculator as the total cost varies per region.
Outcome
Infrastructure diagram for a dual-region EKS setup (click on the image to open the PDF version)
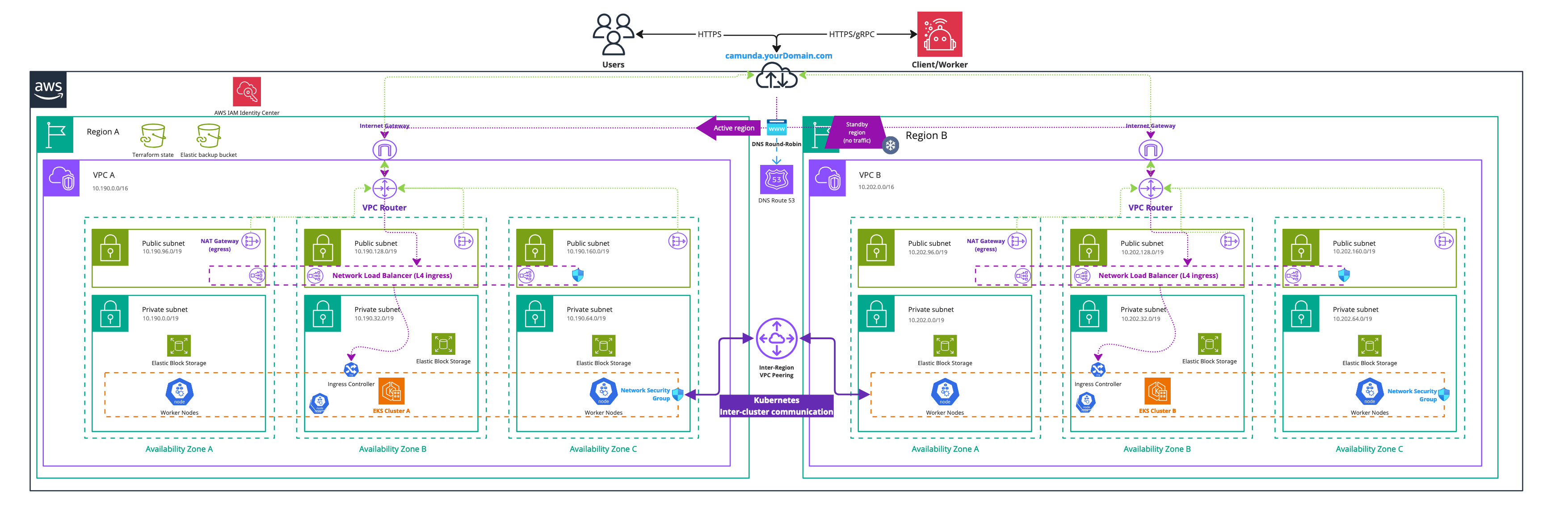
Completion of this tutorial will result in:
- Two Amazon EKS Kubernetes clusters in two different geographic regions with each four nodes ready for the Camunda 8 dual-region installation.
- The EBS CSI driver installed and configured, which is used by the Camunda 8 Helm chart to create persistent volumes.
- A VPC peering between the two EKS clusters, allowing cross-cluster communication between different regions.
- An Amazon Simple Storage Service (S3) bucket for Elasticsearch backups.
Environment prerequisites
There are two regions (REGION_0 and REGION_1), each with its own Kubernetes cluster (CLUSTER_0 and CLUSTER_1).
To streamline the execution of the subsequent commands, it is recommended to export multiple environment variables within your terminal. Additionally, it is recommended to manifest those changes for future interactions with the dual-region setup.
- Git clone or fork the repository c8-multi-region:
git clone https://github.com/camunda/c8-multi-region.git
- The cloned repository and folder
aws/dual-region/scripts/provides a helper script export_environment_prerequisites.sh to export various environment variables to ease the interaction with a dual-region setup. Consider permanently changing this file for future interactions. - You must adjust these environment variable values within the script to your needs.
You have to choose unique namespaces for Camunda 8 installations. The namespace for Camunda 8 installation in the cluster of region 0 (CAMUNDA_NAMESPACE_0), needs to have a different name from the namespace for Camunda 8 installation in the cluster of region 1 (CAMUNDA_NAMESPACE_1). This is required for proper traffic routing between the clusters.
For example, you can install Camunda 8 into CAMUNDA_NAMESPACE_0 in CLUSTER_0, and CAMUNDA_NAMESPACE_1 on the CLUSTER_1, where CAMUNDA_NAMESPACE_0 != CAMUNDA_NAMESPACE_1.
Using the same namespace names on both clusters won't work as CoreDNS won't be able to distinguish between traffic targeted at the local and remote cluster.
- Execute the script via the following command:
. ./export_environment_prerequisites.sh
The dot is required to export those variables to your shell and not a spawned subshell.
loading...
Installing Amazon EKS clusters with Terraform
Prerequisites
- From your cloned repository, navigate to
aws/dual-region/terraform. This contains the Terraform base configuration for the dual-region setup.
Contents elaboration
config.tf
This file contains the backend and provider configuration, meaning where to store the Terraform state and which providers to use, their versions, and potential credentials.
The important part of config.tf is the initialization of two AWS providers, as you need one per region and this is a limitation by AWS given everything is scoped to a region.
It's recommended to use a different backend than local. Find more information in the Terraform documentation.
Do not store sensitive information (credentials) in your Terraform files.
clusters.tf
This file is using Terraform modules, which allows abstracting resources into reusable components.
The Terraform modules of AWS EKS are an example implementation and can be used for development purposes or as a starting reference.
This contains the declaration of the two clusters. One of them has an explicit provider declaration, as otherwise everything is deployed to the default AWS provider, which is limited to a single region.
vpc-peering.tf
For a multi-region setup, you need to have the virtual private cloud (VPC) peered to route traffic between regions using private IPv4 addresses and not publicly route the traffic and expose it. For more information, review the AWS documentation on VPC peering.
VPC peering is preferred over transit gateways. VPC peering has no bandwidth limit and a lower latency than a transit gateway. For a complete comparison, review the AWS documentation.
The previously mentioned Camunda module will automatically create a VPC per cluster.
This file covers the VPC peering between the two VPCs and allow any traffic between those two by adjusting each cluster's security groups.
s3.tf
For Elasticsearch, an S3 bucket is required to allow creating and restoring snapshots. There are alternative ways, but since this is focused on AWS, it makes sense to remain within the same cloud environment.
This file covers the declaration of an S3 bucket to use for the backups. Additionally, a service account with access to use within the Kubernetes cluster to configure Elasticsearch to access the S3 bucket.
output.tf
Terraform outputs allow you to reuse generated values in future steps. For example, the access keys of the service account with S3 access.
variables.tf
This file contains various variable definitions for both local and input types. The difference is that input variables require you to define the value on execution. While local variables are permanently defined, they are namely for code duplication purposes and readability.
Preparation
- Adjust any values in the variables.tf file to your liking. For example, the target regions and their name or CIDR blocks of each cluster.
- Make sure that any adjustments are reflected in your environment prerequisites to ease the in-cluster setup.
- Set up the authentication for the
AWSprovider.
The AWS Terraform provider is required to create resources in AWS. You must configure the provider with the proper credentials before using it. You can further change the region and other preferences and explore different authentication methods.
There are several ways to authenticate the AWS provider:
- (Recommended) Use the AWS CLI to configure access. Terraform will automatically default to AWS CLI configuration when present.
- Set environment variables
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEY, which can be retrieved from the AWS Console.
Execution
A user who creates resources in AWS will therefore own these resources. In this particular case, the user will always have admin access to the Kubernetes cluster until the cluster is deleted.
Therefore, it can make sense to create an extra AWS IAM user which credentials are used for Terraform purposes.
- Open a terminal and navigate to
aws/dual-region/terraform. - Initialize the working directory:
terraform init -upgrade
- Apply the configuration files:
terraform apply
If you have not set a default value for cluster_name, you will be asked to provide a suitable name.
- After reviewing the plan, you can type
yesto confirm and apply the changes.
At this point, Terraform will create the Amazon EKS clusters with all the necessary configurations. The completion of this process may require approximately 20-30 minutes.
In-cluster setup
Now that you have created two peered Kubernetes clusters with Terraform, you will still have to configure various things to make the dual-region work:
Cluster access
To ease working with two clusters, create or update your local kubeconfig to contain those new contexts. Using an alias for those new clusters allows you to directly use kubectl and Helm with a particular cluster.
Update or create your kubeconfig via the AWS CLI:
# the alias allows for easier context switching in kubectl
aws eks --region $REGION_0 update-kubeconfig --name $CLUSTER_0 --alias $CLUSTER_0
aws eks --region $REGION_1 update-kubeconfig --name $CLUSTER_1 --alias $CLUSTER_1
The region and name must align with the values you have defined in Terraform.
DNS chaining
This allows for easier communication between the two clusters by forwarding DNS queries from the region 0 cluster to the region 1 cluster and vice versa.
You are configuring the CoreDNS from the cluster in Region 0 to resolve certain namespaces via Region 1 instead of using the in-cluster DNS server. Camunda applications (e.g. Zeebe brokers) to resolve DNS record names of Camunda applications running in another cluster.
CoreDNS configuration
- Expose
kube-dns, the in-cluster DNS resolver via an internal load-balancer in each cluster:
kubectl --context $CLUSTER_0 apply -f https://raw.githubusercontent.com/camunda/c8-multi-region/main/aws/dual-region/kubernetes/internal-dns-lb.yml
kubectl --context $CLUSTER_1 apply -f https://raw.githubusercontent.com/camunda/c8-multi-region/main/aws/dual-region/kubernetes/internal-dns-lb.yml
- Execute the script generate_core_dns_entry.sh in the folder
aws/dual-region/scripts/of the repository to help you generate the CoreDNS config. Make sure that you have previously exported the environment prerequisites since the script builds on top of it.
./generate_core_dns_entry.sh
- The script will retrieve the IPs of the load balancer via the AWS CLI and return the required config change.
- The script prints the
kubectl editcommands to change the DNS settings of each cluster inline. Copy the statement between the placeholders to edit the CoreDNS configmap in cluster 0 and cluster 1, depending on the placeholder.
An alternative to inline editing is to create two copies of the filekubernetes/coredns.yml, one for each cluster. Add the section generated by the script to each file. Apply the changes to each cluster with e.g.kubectl --context cluster-london -n kube-system apply -f file.yml. Replace thecontextparameter with your current values.
Example output
cautionFor illustration purposes only. These values will not work in your environment.
./generate_core_dns_entry.sh
Please copy the following between
### Cluster 0 - Start ### and ### Cluster 0 - End ###
and insert it at the end of your CoreDNS configmap in Cluster 0
kubectl --context cluster-london -n kube-system edit configmap coredns
### Cluster 0 - Start ###
camunda-paris.svc.cluster.local:53 {
errors
cache 30
forward . 10.202.19.54 10.202.53.21 10.202.84.222 {
force_tcp
}
}
### Cluster 0 - End ###
Please copy the following between
### Cluster 1 - Start ### and ### Cluster 1 - End ###
and insert it at the end of your CoreDNS configmap in Cluster 1
kubectl --context cluster-paris -n kube-system edit configmap coredns
### Cluster 1 - Start ###
camunda-london.svc.cluster.local:53 {
errors
cache 30
forward . 10.192.27.56 10.192.84.117 10.192.36.238 {
force_tcp
}
}
### Cluster 1 - End ###
For illustration purposes only. These values will not work in your environment.
./generate_core_dns_entry.sh
Please copy the following between
### Cluster 0 - Start ### and ### Cluster 0 - End ###
and insert it at the end of your CoreDNS configmap in Cluster 0
kubectl --context cluster-london -n kube-system edit configmap coredns
### Cluster 0 - Start ###
camunda-paris.svc.cluster.local:53 {
errors
cache 30
forward . 10.202.19.54 10.202.53.21 10.202.84.222 {
force_tcp
}
}
### Cluster 0 - End ###
Please copy the following between
### Cluster 1 - Start ### and ### Cluster 1 - End ###
and insert it at the end of your CoreDNS configmap in Cluster 1
kubectl --context cluster-paris -n kube-system edit configmap coredns
### Cluster 1 - Start ###
camunda-london.svc.cluster.local:53 {
errors
cache 30
forward . 10.192.27.56 10.192.84.117 10.192.36.238 {
force_tcp
}
}
### Cluster 1 - End ###
Full configmap example
cautionFor illustration purposes only. This file will not work in your environment.
coredns-cm-london.ymlapiVersion: v1
kind: ConfigMap
metadata:
labels:
eks.amazonaws.com/component: coredns
k8s-app: kube-dns
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
camunda-paris.svc.cluster.local:53 {
errors
cache 30
forward . 10.202.19.54 10.202.53.21 10.202.84.222 {
force_tcp
}
}
For illustration purposes only. This file will not work in your environment.
apiVersion: v1
kind: ConfigMap
metadata:
labels:
eks.amazonaws.com/component: coredns
k8s-app: kube-dns
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
camunda-paris.svc.cluster.local:53 {
errors
cache 30
forward . 10.202.19.54 10.202.53.21 10.202.84.222 {
force_tcp
}
}
- Check that CoreDNS has reloaded for the changes to take effect before continuing. Make sure it contains
Reloading complete:
kubectl --context $CLUSTER_0 logs -f deployment/coredns -n kube-system
kubectl --context $CLUSTER_1 logs -f deployment/coredns -n kube-system
Test DNS chaining
The script test_dns_chaining.sh within the folder aws/dual-region/scripts/ of the repository will help to test that the DNS chaining is working by using nginx pods and services to ping each other.
- Execute the test_dns_chaining.sh. Make sure you have previously exported the environment prerequisites as the script builds on top of it.
./test_dns_chaining.sh
- Watch how a nginx pod and service will be deployed per cluster. It will wait until the pods are ready and finally ping from nginx in cluster 0 the nginx in cluster 1 and vice versa. If it fails to contact the other nginx five times, it will fail.
Deploy Camunda 8 to the clusters
Create the secret for Elasticsearch
Elasticsearch will need an S3 bucket for data backup and restore procedure, required during a regional failback. For this, you will need to configure a Kubernetes secret to not expose those in cleartext.
You can pull the data from Terraform since you exposed those via output.tf.
- From the Terraform code location
aws/dual-region/terraform, execute the following to export the access keys to environment variables. This will allow an easier creation of the Kubernetes secret via the command line:
export AWS_ACCESS_KEY_ES=$(terraform output -raw s3_aws_access_key)
export AWS_SECRET_ACCESS_KEY_ES=$(terraform output -raw s3_aws_secret_access_key)
- From the folder
aws/dual-region/scriptsof the repository, execute the script create_elasticsearch_secrets.sh. This will use the exported environment variables from Step 1 to create the required secret within the Camunda namespaces. Those have previously been defined and exported via the environment prerequisites.
./create_elasticsearch_secrets.sh
- Unset environment variables to reduce the risk of potential exposure. The script is spawned in a subshell and can't modify the environment variables without extra workarounds:
unset AWS_ACCESS_KEY_ES
unset AWS_SECRET_ACCESS_KEY_ES
The Elasticsearch backup bucket is tied to a specific region. If that region becomes unavailable and you want to restore to a different region or S3 services remain disrupted, you must create a new bucket in another region and reconfigure your Elasticsearch cluster to use the new bucket.
Camunda 8 Helm chart prerequisites
Within the cloned repository, navigate to aws/dual-region/kubernetes. This contains a dual-region example setup.
Content elaboration
Our approach is to work with layered Helm values files:
- Have a base
camunda-values.ymlthat is generally applicable for both Camunda installations - Two overlays that are for region 0 and region 1 installations
camunda-values.yml
This forms the base layer that contains the basic required setup, which applies to both regions.
Key changes of the dual-region setup:
global.multiregion.regions: 2- Indicates the use for two regions
global.identity.auth.enabled: false- Identity is currently not supported. Review the limitations section on the dual-region concept page.
global.elasticsearch.disableExporter: true- Disables the automatic Elasticsearch configuration of the Helm chart. We will manually supply the values via environment variables.
identity.enabled: false- Identity is currently not supported.
optimize.enabled: false- Optimize is currently not supported, and has a dependency on Identity.
zeebe.envZEEBE_BROKER_CLUSTER_INITIALCONTACTPOINTS- These are the contact points for the brokers to know how to form the cluster. Find more information on what the variable means in setting up a cluster.
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION0_ARGS_URL- The Elasticsearch endpoint for region 0.
ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION1_ARGS_URL- The Elasticsearch endpoint for region 1.
- A cluster of eight Zeebe brokers (four in each of the regions) is recommended for the dual-region setup
zeebe.clusterSize: 8zeebe.partitionCount: 8zeebe.replicationFactor: 4
elasticsearch.initScripts- Configures the S3 bucket access via a predefined Kubernetes secret.
region0/camunda-values.yml
This overlay contains the multi-region identification for the cluster in region 0.
region1/camunda-values.yml
This overlay contains the multi-region identification for the cluster in region 1.
Preparation
You must change the following environment variables for Zeebe. The default values will not work for you and are only for illustration.
The base camunda-values.yml in aws/dual-region/kubernetes requires adjustments before installing the Helm chart:
ZEEBE_BROKER_CLUSTER_INITIALCONTACTPOINTSZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION0_ARGS_URLZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION1_ARGS_URL
- The bash script generate_zeebe_helm_values.sh in the repository folder
aws/dual-region/scripts/helps generate those values. You only have to copy and replace them within the basecamunda-values.yml. It will use the exported environment variables of the environment prerequisites for namespaces and regions.
./generate_zeebe_helm_values.sh
# It will ask you to provide the following values
# Enter Zeebe cluster size (total number of Zeebe brokers in both Kubernetes clusters):
## For a dual-region setup we recommend eight, resulting in four brokers per region.
Example output
dangerFor illustration purposes only. These values will not work in your environment.
./generate_zeebe_helm_values.sh
Enter Zeebe cluster size (total number of Zeebe brokers in both Kubernetes clusters): 8
Use the following to set the environment variable ZEEBE_BROKER_CLUSTER_INITIALCONTACTPOINTS in the base Camunda Helm chart values file for Zeebe:
- name: ZEEBE_BROKER_CLUSTER_INITIALCONTACTPOINTS
value: camunda-zeebe-0.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-0.camunda-zeebe.camunda-paris.svc.cluster.local:26502,camunda-zeebe-1.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-1.camunda-zeebe.camunda-paris.svc.cluster.local:26502,camunda-zeebe-2.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-2.camunda-zeebe.camunda-paris.svc.cluster.local:26502,camunda-zeebe-3.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-3.camunda-zeebe.camunda-paris.svc.cluster.local:26502
Use the following to set the environment variable ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION0_ARGS_URL in the base Camunda Helm chart values file for Zeebe:
- name: ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION0_ARGS_URL
value: http://camunda-elasticsearch-master-hl.camunda-london.svc.cluster.local:9200
Use the following to set the environment variable ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION1_ARGS_URL in the base Camunda Helm chart values file for Zeebe.
- name: ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION1_ARGS_URL
value: http://camunda-elasticsearch-master-hl.camunda-paris.svc.cluster.local:9200
For illustration purposes only. These values will not work in your environment.
./generate_zeebe_helm_values.sh
Enter Zeebe cluster size (total number of Zeebe brokers in both Kubernetes clusters): 8
Use the following to set the environment variable ZEEBE_BROKER_CLUSTER_INITIALCONTACTPOINTS in the base Camunda Helm chart values file for Zeebe:
- name: ZEEBE_BROKER_CLUSTER_INITIALCONTACTPOINTS
value: camunda-zeebe-0.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-0.camunda-zeebe.camunda-paris.svc.cluster.local:26502,camunda-zeebe-1.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-1.camunda-zeebe.camunda-paris.svc.cluster.local:26502,camunda-zeebe-2.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-2.camunda-zeebe.camunda-paris.svc.cluster.local:26502,camunda-zeebe-3.camunda-zeebe.camunda-london.svc.cluster.local:26502,camunda-zeebe-3.camunda-zeebe.camunda-paris.svc.cluster.local:26502
Use the following to set the environment variable ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION0_ARGS_URL in the base Camunda Helm chart values file for Zeebe:
- name: ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION0_ARGS_URL
value: http://camunda-elasticsearch-master-hl.camunda-london.svc.cluster.local:9200
Use the following to set the environment variable ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION1_ARGS_URL in the base Camunda Helm chart values file for Zeebe.
- name: ZEEBE_BROKER_EXPORTERS_ELASTICSEARCHREGION1_ARGS_URL
value: http://camunda-elasticsearch-master-hl.camunda-paris.svc.cluster.local:9200
- As the script suggests, replace the environment variables within
camunda-values.yml.
Deploy Camunda 8
From the terminal context of aws/dual-region/kubernetes, execute the following:
helm install $CAMUNDA_RELEASE_NAME camunda/camunda-platform \
--version $HELM_CHART_VERSION \
--kube-context $CLUSTER_0 \
--namespace $CAMUNDA_NAMESPACE_0 \
-f camunda-values.yml \
-f region0/camunda-values.yml
helm install $CAMUNDA_RELEASE_NAME camunda/camunda-platform \
--version $HELM_CHART_VERSION \
--kube-context $CLUSTER_1 \
--namespace $CAMUNDA_NAMESPACE_1 \
-f camunda-values.yml \
-f region1/camunda-values.yml
Verify Camunda 8
- Open a terminal and port-forward the Zeebe Gateway via
kubectlfrom one of your clusters. Zeebe is stretching over both clusters and isactive-active, meaning it doesn't matter which Zeebe Gateway to use to interact with your Zeebe cluster.
kubectl --context "$CLUSTER_0" -n $CAMUNDA_NAMESPACE_0 port-forward services/$CAMUNDA_RELEASE_NAME-zeebe-gateway 8080:8080
- Open another terminal and use e.g.
cURLto print the Zeebe cluster topology:
curl -L -X GET 'http://localhost:8080/v2/topology' \
-H 'Accept: application/json'
- Make sure that your output contains all eight brokers from the two regions:
Example output
{
"brokers": [
{
"nodeId": 0,
"host": "camunda-zeebe-0.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 7,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 8,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 1,
"host": "camunda-zeebe-0.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 2,
"role": "leader",
"health": "healthy"
},
{
"partitionId": 7,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 8,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 2,
"host": "camunda-zeebe-1.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 2,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 3,
"role": "leader",
"health": "healthy"
},
{
"partitionId": 8,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 3,
"host": "camunda-zeebe-1.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 2,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 3,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 4,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 4,
"host": "camunda-zeebe-2.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 2,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 3,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 4,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 5,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 5,
"host": "camunda-zeebe-2.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 3,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 4,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 5,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 6,
"host": "camunda-zeebe-3.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 4,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 5,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "leader",
"health": "healthy"
},
{
"partitionId": 7,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 7,
"host": "camunda-zeebe-3.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 5,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 7,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 8,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
}
],
"clusterSize": 8,
"partitionsCount": 8,
"replicationFactor": 4,
"gatewayVersion": "8.6.0"
}
{
"brokers": [
{
"nodeId": 0,
"host": "camunda-zeebe-0.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 7,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 8,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 1,
"host": "camunda-zeebe-0.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 2,
"role": "leader",
"health": "healthy"
},
{
"partitionId": 7,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 8,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 2,
"host": "camunda-zeebe-1.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 2,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 3,
"role": "leader",
"health": "healthy"
},
{
"partitionId": 8,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 3,
"host": "camunda-zeebe-1.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 1,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 2,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 3,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 4,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 4,
"host": "camunda-zeebe-2.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 2,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 3,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 4,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 5,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 5,
"host": "camunda-zeebe-2.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 3,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 4,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 5,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "follower",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 6,
"host": "camunda-zeebe-3.camunda-zeebe.camunda-london",
"port": 26501,
"partitions": [
{
"partitionId": 4,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 5,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "leader",
"health": "healthy"
},
{
"partitionId": 7,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
},
{
"nodeId": 7,
"host": "camunda-zeebe-3.camunda-zeebe.camunda-paris",
"port": 26501,
"partitions": [
{
"partitionId": 5,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 6,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 7,
"role": "follower",
"health": "healthy"
},
{
"partitionId": 8,
"role": "leader",
"health": "healthy"
}
],
"version": "8.6.0"
}
],
"clusterSize": 8,
"partitionsCount": 8,
"replicationFactor": 4,
"gatewayVersion": "8.6.0"
}