Vector Database connector
The Vector Database connector allows embedding, storing, and retrieving Large Language Model (LLM) embeddings.
This enables building AI-based solutions such as context document search, long-term LLM memory, and agentic AI interaction. For an example, see how to add long-term memory to your AI agents.
The Vector Database connector uses the LangChain4j library. Data models and possible implementations are limited to the latest stable released LangChain4j library.
Prerequisites
Before using the Vector Database connector, ensure you understand the concept of LLM embeddings.
To start using the Vector Database connector, ensure you have access to a supported LLM embeddings API to convert document content into vectorized embedding form. You will also need to have write access to a supported database.
Create a connector task
You can apply a connector to a task or event via the append menu. For example:
- From the canvas: Select an element and click the Change element icon to change an existing element, or use the append feature to add a new element to the diagram.
- From the properties panel: Navigate to the Template section and click Select.
- From the side palette: Click the Create element icon.
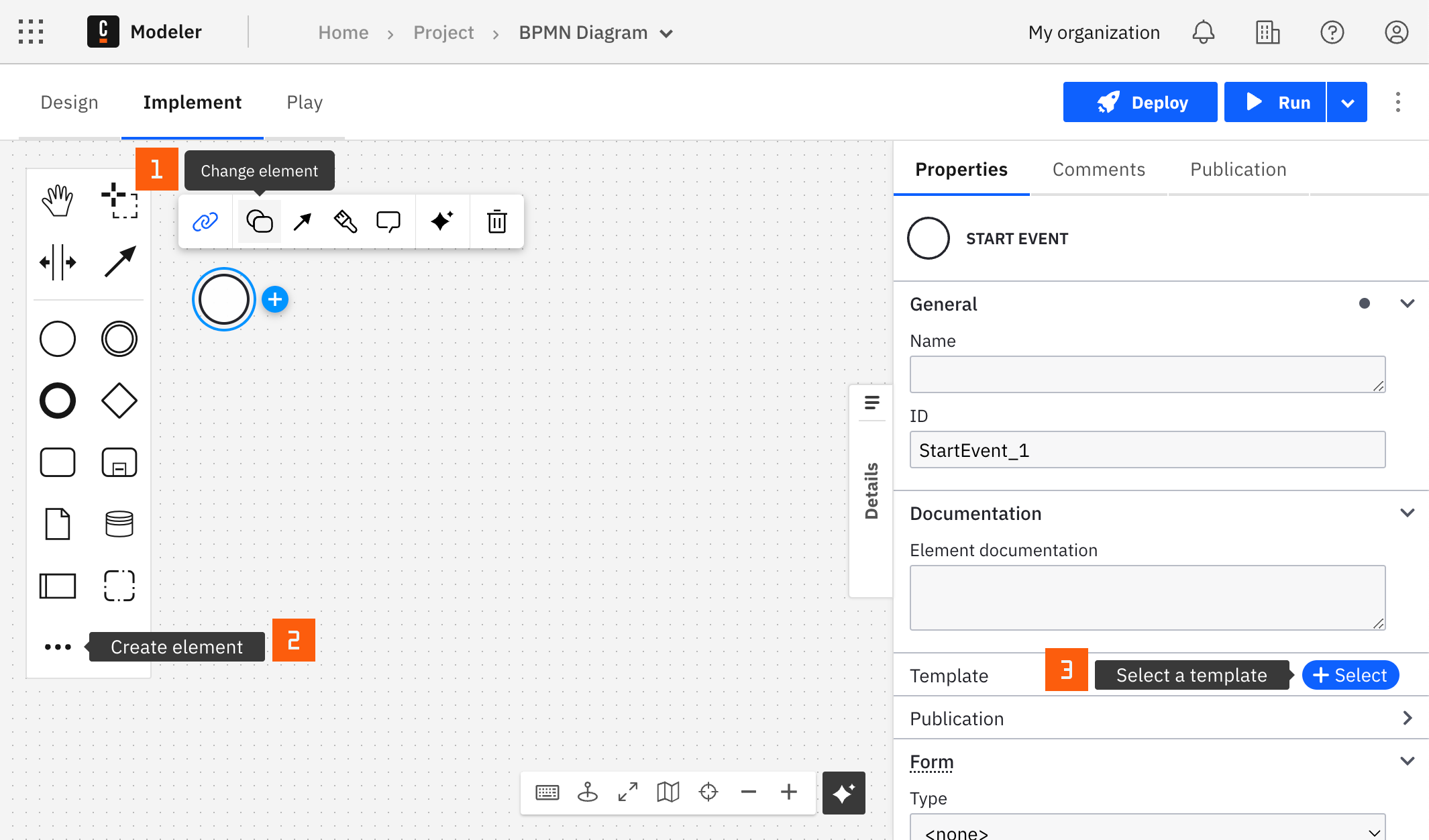
After you have applied a connector to your element, follow the configuration steps or see using connectors to learn more.
Operations
- Embed document
- Retrieve document
The embed document operation performs the following steps:
- Consume a document.
- Parse the document depending on a file format (optionally split into text chunks).
- Convert chunks into a vector form with LLM help.
- Store produced vectors in a vector database.
To perform this operation, enter the following:
- Operation dropdown: Embed document.
- Embedding model: Refer to the relevant section.
- Vector store: Refer to the relevant section.
- Document: Refer to the relevant section.
As a result of this operation, you will get an array of created embedding chunk IDs,
for example ["d599ec62-fe51-4a91-bbf0-26e1241f9079", "a1fad021-5148-42b4-aa02-7de9d590e69c"].
Updating embedded documents
Each time you embed a document, the connector generates a new set of chunks and stores them in the vector database.
If the document was previously embedded, this creates duplicate chunks.
To prevent duplicates:
- Delete the existing chunks before re-embedding the document.
- Use the chunk IDs returned by the previous embedding operation.
- If the embedded document is from Camunda, use the
filenamemetadata field to find the chunk IDs. - Follow your vector store’s documentation for deleting chunks.
The retrieve document operation performs the following steps:
- Consumes a query.
- Convert the query into a vector form with LLM help.
- Perform a vector similarity search on previously-stored LLM embeddings.
- Store results in Camunda document storage.
To perform this operation, enter the following:
- Operation dropdown: Retrieve document.
- Search query: Enter your search query.
- Max results: Enter maximum amount of returned results.
- Min score: Enter the lowest score threshold similarity value; the value should be between 0 and 1, for example, 0.81.
- Embedding model: Refer to the relevant section.
- Vector store: Refer to the relevant section.
As a result of this operation, you will get an array of relevant chunks, where each includes a chunk ID, Camunda document reference metadata, similarity score, and the actual text content.
{
"chunks": [
{
"chunkId": "e30d570b-2a3a-4f4a-9a0c-78f0f1acd383",
"documentReference": {
"storeId": "local",
"documentId": "2b36ec67-a78f-4f99-9371-8c6e5b332838",
"contentHash": "1c232bc1e553c10d00c3327dcca9012b6b4b0758a1c2afaad8b77c80fa1bd36e",
"metadata": {
"size": 116,
"fileName": null,
"processDefinitionId": null,
"processInstanceKey": null,
"customProperties": {},
"expiresAt": null,
"contentType": "text/plain"
},
"camunda.document.type": "camunda"
},
"score": 0.6721556,
"content": "Camunda is a platform for orchestrating and automating business processes. It helps organizations design, execute, and manage workflows, enabling them to optimize processes and improve efficiency."
}
]
}
Embedding models
- Amazon Bedrock
- Azure OpenAI
- Google Vertex AI
- OpenAI
The Vector Database connector supports Amazon Titan V1 and V2 models.
You can also specify any custom model that supports text embedding and is available in your Amazon Bedrock account.
To use Amazon Bedrock as an embedding model, provide:
- Access key – Access key for a user with permissions for the Amazon Bedrock
InvokeModelaction. - Secret key – Secret key for the user associated with the provided access key.
- Region – AWS region where the model is hosted (for example,
us-east-1). See AWS model region support for details. - Model name – One of:
- Amazon Titan V1 –
amazon.titan-embed-text-v1 - Amazon Titan V2 –
amazon.titan-embed-text-v2:0 - Custom model – Name of your custom Amazon Bedrock embedding model.
- Amazon Titan V1 –
When using Amazon Titan V2, you can also specify:
- Embedding dimensions – Number of dimensions for the embedding vector.
- Normalize – Whether to normalize the embedding vector. See AWS blog for more details.
For all models, the following parameter is optional:
- Max retries – Maximum number of retries for the embedding request in case of failure.
To use OpenAI as an embedding model, provide:
- API key – Your OpenAI account API key for authorization.
- Model name – The OpenAI model to use for embeddings. See the OpenAI documentation for available models.
Optional parameters include:
- Organization ID – For projects accessed through a legacy user API key, specify the organization ID for API requests with this connector.
- Project ID – For projects accessed through a legacy user API key, specify the project ID for API requests with this connector.
- Embedding dimensions – Number of dimensions for the embedding vector. If not specified, the default value for the selected model is used.
- Custom headers – Additional headers to include in the request.
- Custom base URL – Base URL for API requests when using a custom OpenAI endpoint.
- Max retries – Maximum number of retries for the embedding request in case of failure.
To use Azure OpenAI as an embedding model, provide:
- Endpoint – The Azure OpenAI endpoint URL, for example
https://<your-resource-name>.openai.azure.com/. - Authentication – Select the authentication type to use with Azure OpenAI.
Optional parameters include:
- Embedding dimensions – Number of dimensions for the embedding vector. If not specified, the default value for the selected model is used.
- Custom headers – Additional headers to include in the request.
- Max retries – Maximum number of retries for the embedding request in case of failure.
Two authentication methods are supported:
- API key – Authenticate using an Azure OpenAI API key from the Azure AI Foundry portal.
- Client credentials – Authenticate using a client ID and secret. This requires registering an application in Microsoft Entra ID. Provide:
- Client ID – The Microsoft Entra application ID.
- Client secret – The application’s client secret.
- Tenant ID – The Microsoft Entra tenant ID.
- Authority host – (Optional) The authority host URL. Defaults to
https://login.microsoftonline.com/. Can also be an OAuth 2.0 token endpoint.
To use Google Vertex AI as an embedding model, provide:
- Project ID – The Google Cloud project ID.
- Region – The region where AI inference should take place.
- Authentication – Select the authentication type for connecting to Google Cloud.
- Model name – The Vertex AI model to use for embeddings. Refer to the Vertex AI documentation for available models.
- Embedding dimensions – Number of dimensions for the embedding vector. Consult the documentation for the selected model for valid ranges.
Optional parameters include:
- Publisher – The publisher of the Vertex AI model. Defaults to
googleif not specified. - Max retries – Maximum number of retries for the embedding request in case of failure.
Two authentication methods are supported:
- Service Account Credentials – Authenticate using a service account key in JSON format.
- Application Default Credentials (ADC) – Authenticate using the default credentials available in your environment.
This method is only supported in Self-Managed or hybrid environments.
To set up ADC in a local development environment, follow the instructions here.
Vector stores
- Amazon OpenSearch
- Azure AI Search
- Azure Cosmos DB NoSQL
- Elasticsearch
- OpenSearch
Enter the following parameters:
- Base URL – The Elasticsearch base URL, including protocol, for example
https://host:port. - Username – For the Elasticsearch user that has read/write access.
- Password – For the Elasticsearch user that has read/write access.
- Index name – Name of the index where you wish to store embeddings.
- When embedding: If the index is not present, the connector will create a new one.
- When retrieving: If the index is absent, the connector will raise an error.
The Elasticsearch version must be 8+.
Enter the following parameters:
- Base URL – The OpenSearch base URL, including protocol, for example
https://host:port. - Username – For the OpenSearch user that has read/write access.
- Password – For the OpenSearch user that has read/write access.
- Index name – Name of the index where you wish to store embeddings.
- When embedding: If the index is not present, the connector will create a new one.
- When retrieving: If the index is absent, the connector will raise an error.
Enter the following parameters:
- Access key and Secret key – Enter AWS IAM credentials for the user that has read/write access.
- Server URL – An Amazon OpenSearch URL without protocol, for example
my-opensearch.aws.com:port. - Region – Region of the Amazon OpenSearch instance.
- Index name – Name of the index where you wish to store embeddings.
- When embedding: If the index is not present, the connector will create a new one.
- When retrieving: If the index is absent, the connector will raise an error.
Enter the following parameters:
- Endpoint – The Azure AI Search endpoint URL, for example
https://<your-resource-name>.search.windows.net/. - Authentication – Select the authentication type for connecting to Azure AI Search.
- Index name – Name of the index where embeddings will be stored.
- When embedding: If the index is not present, the connector will create it.
- When retrieving: If the index is absent, the connector will raise an error.
Two authentication methods are supported:
-
API key – Authenticate using an Azure AI Search key.
-
Client credentials – Authenticate using a client ID and secret.
This requires registering an application in Microsoft Entra ID and assigning the required roles.
Role-based access control must be explicitly enabled for the Azure AI Search resource.Provide the following fields:
- Client ID – The Microsoft Entra application ID.
- Client secret – The application’s client secret.
- Tenant ID – The Microsoft Entra tenant ID.
- Authority host – (Optional) The authority host URL. Defaults to
https://login.microsoftonline.com/. This can also be an OAuth 2.0 token endpoint.
Enter the following parameters:
- Endpoint – The Azure Cosmos DB NoSQL endpoint URL, for example
https://<your-resource-name>.documents.azure.com/. - Authentication – Select the authentication type for connecting to Azure Cosmos DB NoSQL.
- Database name – The name of the Azure Cosmos DB NoSQL database.
- Container name – The name of the Azure Cosmos DB NoSQL container.
Note: The container must already exist and have an/idpartition key. - Consistency level – The consistency level for the container. Defaults to
Eventual. - Distance function – The distance function to use for vector similarity search. Defaults to
Cosine. - Vector index type – The vector index type to use. Defaults to
Flat.
For more information about Azure Cosmos DB NoSQL vector search, refer to the official documentation.
Pay special attention to the vector dimensions limitations as stated in the documentation.
Two authentication methods are supported:
-
API key – Authenticate using an Azure Cosmos DB key.
-
Client credentials – Authenticate using a client ID and secret.
This requires registering an application in Microsoft Entra ID.Provide the following fields:
- Client ID – The Microsoft Entra application ID.
- Client secret – The application’s client secret.
- Tenant ID – The Microsoft Entra tenant ID.
- Authority host – (Optional) The authority host URL. Defaults to
https://login.microsoftonline.com/. Can also be an OAuth 2.0 token endpoint.
Embedding document configuration
Document source
The Document source can be either Plain text or a Camunda document.
Plain text can be useful when you deal with small size data that can fit into a text field or a process variable. Input will be handled as a regular UTF-8 text.
A FEEL string conversion function might be useful if you have JSON input.
The Camunda document might be useful when you deal with larger document pipelines that come from webhook or user tasks. Input documents will be parsed with Apache Tika, so files can be of any Apache Tika-supported formats.
Splitting
Splitting is an action of breaking large documents into smaller pieces. It can be either recursive or no splitting at all. Seek guidance from your local data scientist to determine if you require splitting.
Learn more about splitting in the LangChain4j documentation.
HTTP proxy configuration
In Self-Managed environments, the Vector Database connector supports routing HTTP requests through an HTTP proxy. This applies to both embedding model API calls and vector store connections.
The Vector Database connector supports plain proxy variables in addition to the standard connector proxy variables. Refer to the HTTP proxy configuration page for the full list of environment variables and configuration options.
The following providers do not support connector proxy variables, but respect standard JVM proxy properties:
- Google VertexAI (embedding model).
- Azure AI Search (vector store).
The following providers do not support proxy configuration:
- Azure Cosmos DB NoSQL (vector store).
To disable proxy support entirely (for example, if only an HTTPS-based proxy is available), set the following environment variable:
CAMUNDA_CONNECTOR_VECTORDB_HTTP_PROXYSUPPORT_ENABLED=false