Amazon Bedrock Code Interpreter connector
With the Amazon Bedrock Code Interpreter outbound connector, you can execute Python code in a secure Amazon Bedrock AgentCore Code Interpreter sandbox from your BPMN process.
Prerequisites
To use the Amazon Bedrock Code Interpreter connector, you need the following:
- An AWS account with an access key and secret key, or a configured default credentials chain.
- IAM permissions to execute the following actions on the
bedrock-agentcoreservice:StartCodeInterpreterSessionInvokeCodeInterpreterStopCodeInterpreterSession
- The AgentCore Code Interpreter service must be available in your selected AWS region.
Learn more about the AgentCore Code Interpreter in the official documentation.
Use Camunda secrets to store credentials and avoid exposing sensitive information directly from the process. Refer to managing secrets to learn more.
Create an Amazon Bedrock Code Interpreter connector task
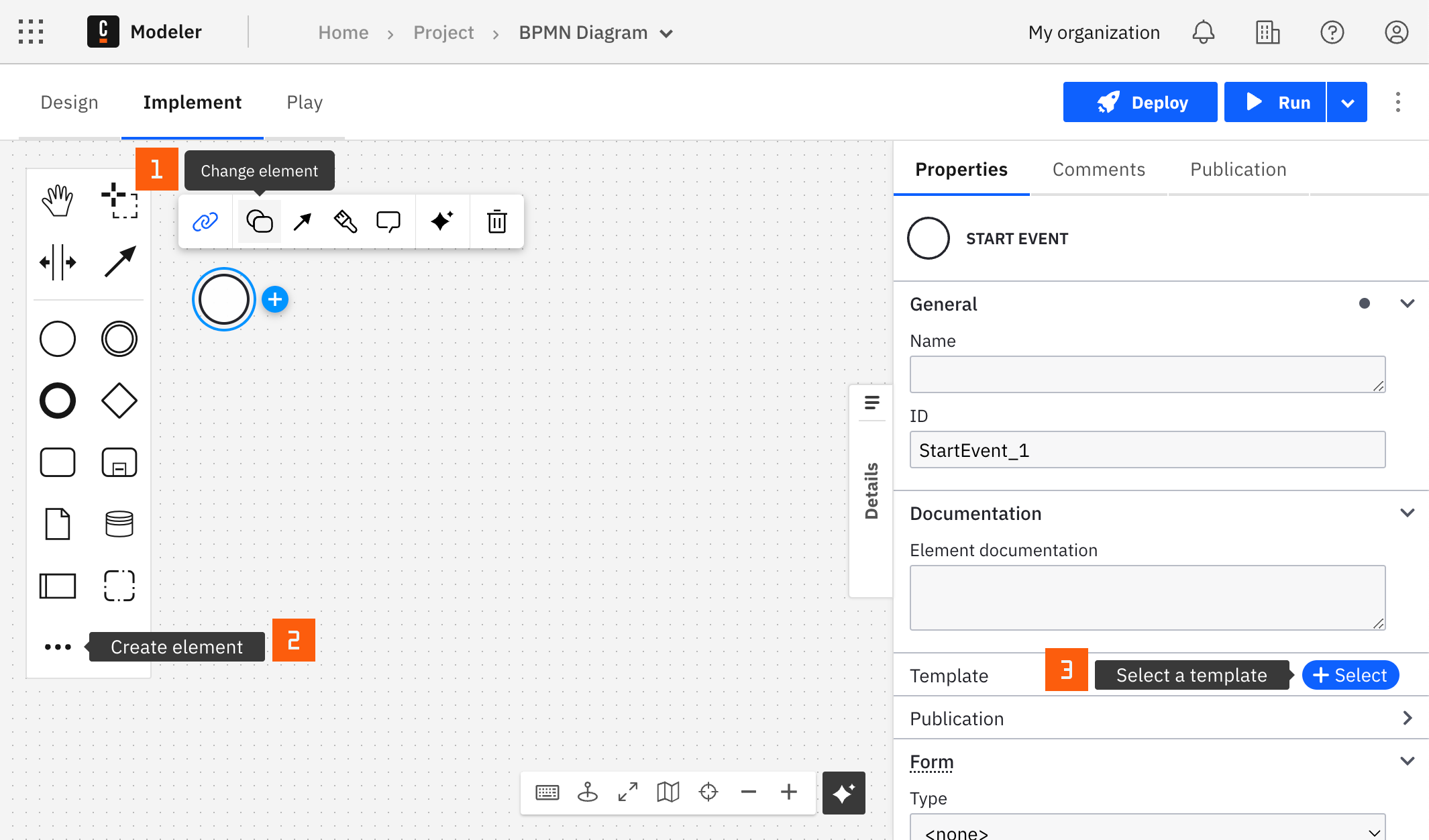
You can apply a connector to a task or event via the append menu. For example:
- From the canvas: Select an element and click the Change element icon to change an existing element, or use the append feature to add a new element to the diagram.
- From the properties panel: Navigate to the Template section and click Select.
- From the side palette: Click the Create element icon.
After you have applied a connector to your element, follow the configuration steps or see using connectors to learn more.
Authentication
To authenticate, choose one of the methods from the Authentication dropdown. The supported options are:
- Use Credentials if you have a valid pair of access and secret keys provided by your AWS account administrator.
This option is applicable for both SaaS and Self-Managed users.
- Use Default Credentials Chain if your system is configured as an implicit authentication mechanism, such as role-based authentication, credentials supplied via environment variables, or files on target host. This approach uses the Default Credential Provider Chain to resolve required credentials.
This option is applicable only for Self-Managed or hybrid distributions.
For more information on authentication and security in Amazon Bedrock, see Amazon Bedrock security and privacy.
Configuration
In the Region field, enter the AWS region where Amazon Bedrock AgentCore Code Interpreter is available. For example, us-east-1.
Action
The Amazon Bedrock Code Interpreter connector supports the following action.
Code execution
Parameters
| Parameter | Required | Description |
|---|---|---|
| Code | Yes | The Python code to execute in the sandbox. Supports FEEL expressions. |
| Session timeout (seconds) | No | How long the sandbox session stays alive, in seconds (60–28,800). Defaults to 300. |
The session timeout controls how long the sandbox environment remains available, not how long the code takes to execute. Code execution typically completes in seconds.
The sandbox environment includes common Python libraries such as matplotlib, pandas, numpy, and csv. Network access is not available in the sandbox.
Response
The connector returns the following fields:
| Field | Description |
|---|---|
stdout | The standard output printed by the code. |
stderr | Any error output produced during execution. |
exitCode | The process exit code. A value of 0 indicates successful execution. |
executionTimeMs | The execution duration in milliseconds. |
files | A list of Camunda documents for any files generated by the code. |
File handling
Any files created by the code during execution are automatically detected and returned as Camunda documents in the files field. This includes images (for example, charts saved with plt.savefig()), CSV files, text files, and other output files.
A maximum of 10 files are retrieved per execution, with a total size limit of 10 MB. Files exceeding these limits are skipped, and a warning is logged.
Output mapping
- Use Result Variable to store the response in a process variable. For example,
codeResult. - Use Result Expression to map specific fields from the response into process variables.
For example, to extract the output and generated files:
= {
output: stdout,
files: files
}
Example: Run a calculation
Code:
total = sum([12000, 8500, 15000, 9200])
print(f"Total claims: ${total:,}")
Response:
{
"stdout": "Total claims: $44,700\n",
"stderr": "",
"exitCode": 0,
"executionTimeMs": 0.05,
"files": []
}
Example: Generate a chart
Code:
import matplotlib.pyplot as plt
plt.bar(["Q1", "Q2", "Q3", "Q4"], [12000, 8500, 15000, 9200])
plt.title("Claims by Quarter")
plt.ylabel("Amount ($)")
plt.savefig("chart.png")
print("Chart saved")
Response:
{
"stdout": "Chart saved\n",
"stderr": "",
"exitCode": 0,
"executionTimeMs": 1.67,
"files": [
{
"storeId": "in-memory",
"documentId": "851505b2-61bd-4717-9c86-07678b67f033",
"metadata": {
"contentType": "image/png",
"size": 14734,
"fileName": "chart.png"
},
"camunda.document.type": "camunda"
}
]
}
Example: Generate a CSV report
Code:
import csv
with open("claims.csv", "w", newline="") as f:
w = csv.writer(f)
w.writerow(["ClaimID", "Amount", "Status"])
w.writerows([["C001", 45000, "Rejected"], ["C002", 12000, "Approved"]])
print("Report created")
Response:
{
"stdout": "Report created\n",
"stderr": "",
"exitCode": 0,
"executionTimeMs": 0.05,
"files": [
{
"storeId": "in-memory",
"documentId": "c209e3a4-cefa-4622-adc1-88c92bf06bb2",
"metadata": {
"contentType": "text/csv",
"size": 80,
"fileName": "claims.csv"
},
"camunda.document.type": "camunda"
}
]
}