AI Agent Task connector
Implement an AI agent using an AI Agent connector applied to a service task, paired with an optional ad-hoc sub-process to provide tools usable by the AI.
- For more information and usage examples, see AI Agent Task.
- The example integration page outlines how to model an agentic AI process using the AI Agent Task implementation.
Configuration
Model provider
Select and configure authentication for the LLM model Provider you want to use, from the following supported providers:
- Anthropic (Claude models)
- Amazon Bedrock
- Azure OpenAI
- Google Vertex AI
- OpenAI
- OpenAI-compatible
- Different setup/authentication fields are shown depending on the provider you select.
- Use connector secrets to store credentials and avoid exposing sensitive information directly from the process.
Timeout handling
The default timeout for model API calls is set to three minutes by the runtime. Self-managed Spring connector runtime instances allow you to override this value by setting the camunda.connector.agenticai.aiagent.chat-model.api.default-timeout property in the Spring application properties file.
You can also specify a custom timeout per provider in the Timeout field below. This value takes precedence over the default timeout.
All values must be provided in the ISO-8601 duration format, for example, PT60S for a 60-second timeout.
For more details, see the individual provider sections below, especially for any provider-specific limitations.
The timeout setting must not exceed the job worker timeout; otherwise, the job may be reassigned by the engine while the model call is still in progress.
Anthropic
Select this option to use an Anthropic Claude LLM model (uses the Anthropic Messages API).
| Field | Required | Description |
|---|---|---|
| Anthropic API key | Yes | Your Anthropic account API key for authorization to the Anthropic Messages API. |
| Timeout | No | Provide a timeout for Model API calls in the ISO-8601 Duration Format, for example, PT60S for a 60-second timeout. If left unspecified, system defaults are used. |
For more information about Anthropic Claude LLM models, refer to the Claude models overview.
Amazon Bedrock
Select this option to use a model provided by the Amazon Bedrock service, using the Converse API.
| Field | Required | Description |
|---|---|---|
| Region | Yes | The AWS region. For example, us-east-1. |
| Authentication | Yes | Select the authentication method you want to use for the connector to authenticate with AWS. See Amazon Bedrock connector authentication for more details. |
| Timeout | No | Provide a timeout for Model API calls in the ISO-8601 Duration Format, for example, PT60S for a 60-second timeout. If left unspecified, system defaults are used. |
To authenticate, choose one of the methods from the Authentication dropdown. The supported options are:
- Use Credentials if you have a valid pair of access and secret keys provided by your AWS account administrator. The access key provides permissions to the Amazon Bedrock
InvokeModelactions, as mentioned in the AWS documentation.
This option is applicable for both SaaS and Self-Managed users.
- Use API Key if you have a valid long-term API key for Amazon Bedrock. The associated IAM user also requires the
CallWithBearerTokenaction to be attached. See Amazon Bedrock API keys and Amazon Bedrock API keys permissions for more details.
This option is applicable for both SaaS and Self-Managed users.
- Use Default Credentials Chain if your system is configured as an implicit authentication mechanism, such as role-based authentication, credentials supplied via environment variables, or files on target host. This approach uses the Default Credential Provider Chain to resolve required credentials.
This option is applicable only for Self-Managed or hybrid distributions.
For more information on authentication and security in Amazon Bedrock, see Amazon Bedrock security and privacy.
Model availability depends on the region and model you use. You might need to request a model is made available for your account. To learn more about configuring access to foundation models, refer to access to Amazon Bedrock foundation models.
For a list of Amazon Bedrock LLM models, refer to supported foundation models in Amazon Bedrock.
Azure OpenAI
Select this option to use Azure OpenAI models.
| Field | Required | Description |
|---|---|---|
| Endpoint | Yes | The Azure OpenAI endpoint URL. For example, https://<your-resource-name>.openai.azure.com/ |
| Authentication | Yes | Select the authentication method you want to use for the connector to authenticate with Azure OpenAI. |
| Timeout | No | Provide a timeout for Model API calls in the ISO-8601 Duration Format, for example, PT60S for a 60-second timeout. If left unspecified, system defaults are used. |
Two authentication methods are currently supported:
-
API key: Authenticate using an Azure OpenAI API key, available in the Azure AI Foundry portal.
-
Client credentials: Authenticate using a client ID and secret. This method requires registering an application in Microsoft Entra ID. Provide the following fields:
- Client ID – The Microsoft Entra application ID.
- Client secret – The application’s client secret.
- Tenant ID – The Microsoft Entra tenant ID.
- Authority host – (Optional) The authority host URL. Defaults to
https://login.microsoftonline.com/. This can also be an OAuth 2.0 token endpoint.
To use an Azure OpenAI model, you must first deploy it in the Azure AI Foundry portal. For details, see Deploy a model in Azure OpenAI. The deployment ID must then be provided in the Model field.
Google Vertex AI
Select this option to use Google Vertex AI models.
| Field | Required | Description |
|---|---|---|
| Project ID | Yes | The Google Cloud project ID. |
| Region | Yes | The region where AI inference should take place. |
| Authentication | Yes | Select the authentication method you want to use for the connector to authenticate with Google Cloud. |
Timeout settings are currently not supported for Google Vertex AI models.
Two authentication methods are currently supported:
- Service Account Credentials: Authenticate using a service account key in JSON format.
- Application Default Credentials (ADC): Authenticate using the default credentials available in your environment.
This method is only supported in Self-Managed or hybrid environments.
To set up ADC in a local development environment, follow the instructions here.
For more information about Google Vertex AI models, see the Vertex AI documentation.
OpenAI
Select this option to use the OpenAI Chat Completion API.
| Field | Required | Description |
|---|---|---|
| OpenAI API key | Yes | Your OpenAI account API key for authorization. |
| Organization ID | No | For members of multiple organizations. If you belong to multiple organizations, specify the organization ID to use for API requests with this connector. |
| Project ID | No | If you access projects through a legacy user API key, specify the project ID to use for API requests made with this connector. |
| Timeout | No | Provide a timeout for Model API calls in the ISO-8601 Duration Format, for example, PT60S for a 60-second timeout. If left unspecified, system defaults are used. |
To learn more about authentication to the OpenAPI API, refer to OpenAPI platform API reference.
OpenAI-compatible
Select this option to use an LLM provider that provides OpenAI-compatible endpoints.
| Field | Required | Description |
|---|---|---|
| API endpoint | Yes | The base URL of the OpenAI-compatible endpoint. For example, https://api.your-llm-provider.com/v1 |
| API key | No | The API key for authentication. Leave blank if you are using HTTP headers for authentication. If an Authorization header is specified in the headers, the API key is ignored. |
| Headers | No | Optional HTTP headers to include in the request to the OpenAI-compatible endpoint. |
| Query Parameters | No | Optional query parameters to include in the request URL to the OpenAI-compatible endpoint. |
| Timeout | No | Provide a timeout for Model API calls in the ISO-8601 Duration Format, for example, PT60S for a 60-second timeout. If left unspecified, system defaults are used. |
A Custom parameters field is available in the model parameters to provide any additional parameters supported by your OpenAI-compatible provider.
Model
Select the model you want to use for the selected provider, and specify any additional model parameters.
| Field | Required | Description |
|---|---|---|
| Model | Yes | Specify the model ID for the model you want to use. Example: |
| Maximum tokens | No | The maximum number of tokens per request to allow in the generated response. |
| Maximum completion tokens | No | The maximum number of tokens per request to generate before stopping. |
| Temperature | No | Floating point number, typically between 0 and 1 (0 and 2 for OpenAI). The higher the number, the more randomness will be injected into the response. |
| top P | No | Floating point number, typically between 0 and 1. Recommended for advanced use cases only (usually you only need to use temperature). |
| top K | No | Integer greater than 0. Recommended for advanced use cases only (you usually only need to use temperature). |
- Different model parameter fields are shown depending on the provider/model you select. Additionally, some parameters may be different or have different value ranges (for example, OpenAI Temperature uses a number range between 0 to 2, whereas other models use a range between 0 to 1).
- For more information on each model parameter, refer to the provider documentation links in the element template.
- Parameters that set maximum values (such as maximum tokens) are considered per LLM request, not for the whole conversation. Depending on the provider, the exact meaning of these parameters may vary.
System prompt
The System Prompt is a crucial part of the AI Agent connector configuration, as it defines the behavior and goal of the agent and instructs the LLM on how to act.
| Field | Required | Description |
|---|---|---|
| System prompt | Yes | Specify a system prompt to define how the LLM should act.
|
User Prompt
The User Prompt contains the actual request to the LLM model.
| Field | Required | Description |
|---|---|---|
| User prompt | Yes | This could either contain the initial request or a follow-up request as part of a response interaction feedback loop.
|
| Documents | No | Add a document references list to allow an AI agent to interact with documents and images.
|
Supported document types
As file type support varies by LLM provider/model, you must test your document use case with the provider you are using.
| File type | Supported | Description |
|---|---|---|
| Text | Yes | Text files (MIME types matching text/*, application/xml, application/json, or application/yaml) are passed as plain text content blocks. |
| Yes | PDF files (MIME types matching application/pdf) are passed as base64 encoded content blocks. | |
| Image | Yes | Image files (MIME types matching image/jpg, image/png, image/gif, or image/webp) are passed as base64 encoded content blocks. |
| Audio/video/other | No | Audio and video files are not currently supported, and will result in an error if passed. All other unsupported file types not listed here will also result in an error if passed. |
To learn more about storing, tracking, and managing documents in Camunda 8, see document handling.
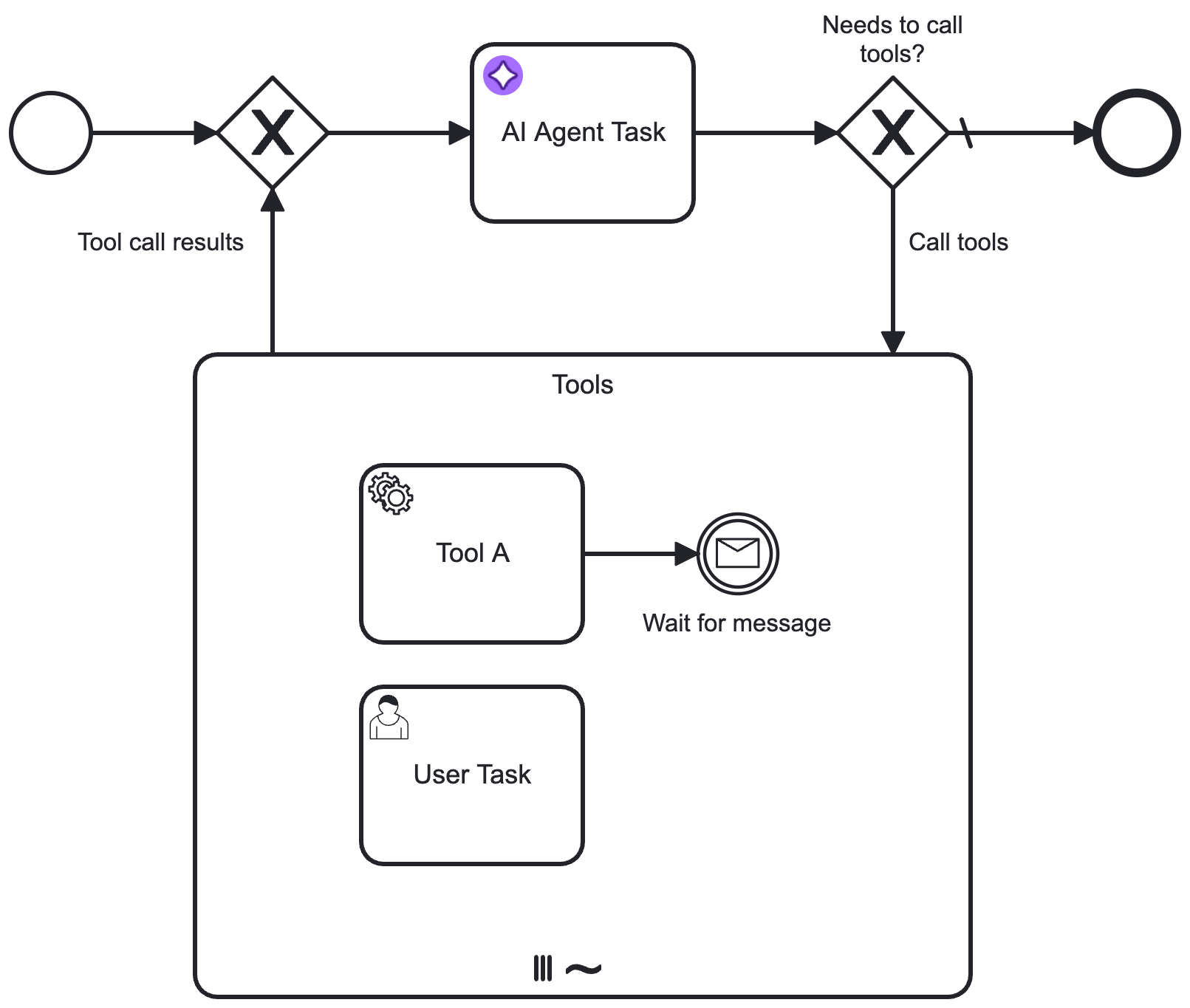
Tools
Specify the tool resolution for an accompanying ad-hoc sub-process.
| Field | Required | Description |
|---|---|---|
| Ad-hoc sub-process ID | No | Specify the element ID of the ad-hoc sub-process to use for tool resolution (see Tool Definitions). When entering the AI Agent connector, the connector resolves the tools available in the ad-hoc sub-process, and passes these to the LLM as part of the prompt. |
| Tool call results | No | Specify the results collection of the ad-hoc sub-process multi-instance execution. Example: |
- Leave this section empty if using this connector independently, without an accompanying ad-hoc sub-process.
- To actually use the tools, you must model your process to include a tools feedback loop, routing into the ad-hoc sub-process and back to the AI agent connector. See example tools feedback loop.
Memory
Configure the agent's short-term/conversational memory.
For the AI Agent Task implementation, the agent context field is required to enable a feedback loop between user requests, tool calls, and LLM responses.
| Field | Required | Description |
|---|---|---|
| Agent context | Yes | Specify an agent context variable to store all relevant data for the agent to support a feedback loop between user requests, tool calls, and LLM responses. Make sure this variable points to the This is an important variable required to make a feedback loop work correctly. This variable must be aligned with the Output mapping Result variable and Result expression for this connector. Avoid reusing the agent context variable across different agent tasks. Define a dedicated result variable name for each agent instead and align it in the context and the result configuration. Example: |
Depending on your use case, you can store the conversation memory in different storage backends.
| Field | Required | Description |
|---|---|---|
| Memory storage type | Yes | Specify how the conversation memory should be stored.
|
| Context window size | No | Specify the maximum number of messages to pass to the LLM on every call. Defaults to
|
In-process storage
Messages passed between the AI agent and the model are stored within the agent context variable and directly visible in Operate.
This is suitable for many use cases, but you must be aware of the variable size limitations that limit the amount of data that can be stored in the process variable.
Camunda document storage
Messages passed between the AI agent and the model are not directly available as process variable but reference a JSON document stored in document storage.
As documents are subject to expiration, to avoid losing the conversation history you must be able to predict the expected lifetime of your process, so you can correctly configure the document time-to-live (TTL).
| Field | Required | Description |
|---|---|---|
| Document TTL | No | Time-to-live (TTL) for documents containing the conversation history. Use this field to set a custom TTL matching your expected process lifetime. The default cluster TTL is used if this value is not configured. |
| Custom document properties | No | Optional map of properties to store with the document. Use this option to reference custom metadata you might want to use when further processing conversation documents. |
Custom implementation
This option is only supported if you are using a customized AI Agent connector in a Self-Managed or hybrid setup. See customization for more details.
| Field | Required | Description |
|---|---|---|
| Implementation type | Yes | The type identifier of your custom storage implementation. See customization for an example. |
| Parameters | No | Optional map of parameters to be passed to the storage implementation. |
Limits
Set limits for the agent interaction to prevent unexpected behavior or unexpected cost due to infinite loops.
| Field | Required | Description |
|---|---|---|
| Maximum model calls | No | Specify the maximum number of model calls. As a safeguard, this limit defaults to a value of 10 if you do not configure this value. |
Despite these limits, you must closely monitor your LLM API usage and cost, and set appropriate limits on the provider side.
Response
Configure the response format by specifying how the model should return its output (text or JSON) and how the connector should process and handle the returned response.
The outcome of an LLM call is stored as an assistant message designed to contain multiple content blocks.
- This message always contains a single text content block for the currently supported providers/models.
- The connector returns the first content block when handling the response, either as a text string or as a parsed JSON object.
| Field | Required | Description |
|---|---|---|
| Response format | Yes | Instructs the model which response format to return.
|
| Include assistant message | No | Returns the entire message returned by the LLM as Select this option if you need more than just the first response text. |
Text response format
If not configured otherwise, this format is used by default and returns a responseText string as part of the
connector response.
| Field | Required | Description |
|---|---|---|
| Parse text as JSON | No | If this option is selected, the connector will attempt to parse the response text as JSON and return the parsed object as
|
For an example prompt that instructs the model to return a JSON response, (see Anthropic documenation):
Output in JSON format with keys: "sentiment" (positive/negative/neutral), "key_issues" (list), and "action_items" (list of dicts with "team" and "task").
JSON response format
The JSON response format is currently only supported for OpenAI and Google Vertex AI models. Use the text response format in combination with the Parse text as JSON option for other providers.
If the model supports it, selecting JSON as response format instructs the model to always return a JSON response. If the model does not return a valid JSON response, the connector throws an error.
To ensure the model generates data according to a specific JSON structure, you can optionally provide a JSON Schema. Alternatively, you can instruct the model to return JSON following a specific structure as shown in the text example above.
Support for JSON responses varies by provider and model.
For OpenAI, selecting the JSON response format is equivalent to using the JSON mode. Providing a JSON Schema instructs the model to return structured outputs.
| Field | Required | Description |
|---|---|---|
| Response JSON schema | No | Describes the desired response format as JSON Schema.
|
| Response JSON schema name | No | Depending on the provider, the schema must be configured with a name for the schema (such as Ideally this name describes the purpose of the schema to make the model aware of the expected data. |
For example, the following shows an example JSON Schema describing the expected response format for a user profile:
={
"type": "object",
"properties": {
"userId": {
"type": "number"
},
"firstname": {
"type": "string"
},
"lastname": {
"type": "string"
}
},
"required": [
"userId",
"firstname",
"lastname"
]
}
Assistant message
If the Include assistant message option is selected, the response from the AI Agent connector contains a
responseMessage object that includes the assistant message, including all content blocks and metadata. For example:
{
"responseMessage": {
"role": "assistant",
"content": [
{
"type": "text",
"text": "Based on the result from the GetDateAndTime function, the current date and time is:\n\nJune 2, 2025, 09:15:38 AM (Central European Summer Time)."
}
],
"metadata": {
"framework": {
"tokenUsage": {
"inputTokenCount": 1563,
"outputTokenCount": 95,
"totalTokenCount": 1658
},
"finishReason": "STOP"
}
}
}
}
To retrieve the response text from the responseMessage object, use the following FEEL expression (assuming the response variable is named agent):
agent.responseMessage.content[type = "text"][1].text
Output mapping
Specify the process variables that you want to map and export the AI Agent connector response into.
| Field | Required | Description |
|---|---|---|
| Result variable | Yes | The result of the AI Agent connector is a context containing the following fields. Set this to a unique value for every agent task in your process to avoid interference between agents.
Response fields depend on how the Response is configured:
|
| Result expression | No | In addition, you can choose to unpack the content of the response into multiple process variables using the Result expression field, as a FEEL Context Expression. |
To model your first AI Agent, you can use the default result variable (agent) and
configure the Agent Context as agent.context.
When adding a second AI Agent connector, use a
different variable name (such as mySecondAgent) and align the context variable accordingly (for example, mySecondAgent.context) to avoid interference and
unexpected results between different agents.
To learn more about output mapping, see variable/response mapping.
Error handling
If an error occurs, the AI Agent connector throws an error and includes the error response in the error variable in Operate.
| Field | Required | Description |
|---|---|---|
| Error expression | No | You can handle an AI Agent connector error using an Error Boundary Event and error expressions. |
In the error expression, you can handle the following error codes emitted by the AI Agent connector to respond to specific situations. For example, you can map a specific error code to a BPMN error and model your process accordingly.
| Error code | Description |
|---|---|
FAILED_MODEL_CALL | The call to the LLM API failed, for example, due to misconfiguration or invalid credentials. The error message contains additional details. |
FAILED_TO_PARSE_RESPONSE_CONTENT | The AI Agent was configured to parse the LLM response as JSON, but parsing failed. |
MAXIMUM_NUMBER_OF_MODEL_CALLS_REACHED | The AI Agent reached the configured maximum number of model calls. |
MIGRATION_MISSING_TOOLS | Tools referenced by the AI Agent were removed after a process instance migration. Removing or renaming tools is not supported. See process instance migrations for more details. |
MIGRATION_GATEWAY_TOOL_DEFINITIONS_CHANGED | Gateway tool definitions have changed after a process instance migration. Adding or removing gateway tools to a running agent is not supported. See process instance migrations for more details. |
NO_USER_MESSAGE_CONTENT | No user message content, either from a user prompt or a document, was provided to the agent. |
TOOL_CALL_RESULTS_ON_EMPTY_CONTEXT | Tool call results were passed to the AI Agent despite an empty context, which typically indicates a misconfiguration of the agent context. |
The AI Agent Task generates the following error codes when creating the tool schema from the process definition XML:
| Error code | Description |
|---|---|
AD_HOC_SUB_PROCESS_XML_FETCH_ERROR | The process definition XML could not be fetched. |
AD_HOC_SUB_PROCESS_NOT_FOUND | The ad-hoc sub-process with the configured ID could not be found in the process definition XML. |
AD_HOC_TOOL_DEFINITION_INVALID | The ad-hoc sub-process contains invalid tool definitions which can't be transformed into a tool schema. |
Retries
Specify connector execution retry behavior if execution fails.
| Field | Required | Description |
|---|---|---|
| Retries | No | Specify the number of retries (times) the connector repeats execution if it fails. |
| Retry backoff | No | Specify a custom Retry backoff interval between retries instead of the default behavior of retrying immediately. |
Execution listeners
Add and manage execution listeners to allow users to react to events in the workflow execution lifecycle by executing custom logic.
Limitations
No event handling support
Unlike the AI Agent Sub-process implementation, the AI Agent Task implementation does not support event handling as part of an event subprocess.
If you want to handle events while the AI agent is working on a task, use the AI Agent Sub-process implementation instead.
Process definition not found errors when running the AI Agent for the first time
The AI Agent Task implementation relies on the eventually consistent Get process definition XML API to fetch the BPMN XML source when resolving available tool definitions.
- If you deploy a new or changed process and directly run it after (for example using Deploy & Run), the process definition might not be available when the AI Agent attempts to fetch the process definition XML.
- It will retry to fetch the definition several times, but if the definition is still not available after the retries are exhausted, the connector will fail with a "Process definition not found" error and raise an incident.
To avoid this error, wait a few seconds before running a newly deployed new or changed process, to allow the exporter to make the process definition available via the API.