AI Agent connector
Use the AI Agent connector to integrate Large Language Models (LLMs) with AI agents to build solutions using agentic orchestration.
About this connector
The AI Agent connector enables AI agents to integrate with an LLM to provide interaction/reasoning capabilities. This connector is designed for use with an ad-hoc sub-process in a feedback loop, providing automated user interaction and tool selection.
For example, use this connector to enable an AI agent to autonomously select and execute tasks within ad-hoc sub-processes by evaluating the current process context and determining the relevant tasks and tools to use in response. You can also use the AI Agent connector independently, although it is designed to be used with an ad-hoc sub-process to define the tools an AI agent can use.
Core features include:
| Feature | Description |
|---|---|
| LLM provider support | Supports a range of LLM providers, such as Anthropic, Amazon Bedrock, Google Gemini, and OpenAI. |
| Memory | Provides conversational/short-term memory handling to enable feedback loops. For example, this allows a user to ask follow-up questions to an AI agent response. |
| Tool calling | Support for an AI agent to interact with tasks within an ad-hoc sub-process, allowing use of all Camunda features such as connectors and user tasks (human-in-the-loop). Automatic tool resolution allows an AI agent to identify the tools available in an ad-hoc sub-process. |
New to agentic orchestration?
- The Build your first AI Agent guide provides a quick introduction to agentic orchestration and how to use the AI Agent Sub-process connector using a blueprint.
- See the example AI Agent connector integration for a worked example of a simple Agent AI feedback loop model.
- See additional resources for examples of how you can use the AI Agent connector.
Prerequisites
The following prerequisites are required to use this connector:
| Prerequisite | Description |
|---|---|
| Set up your LLM model provider and authentication | Prior to using this connector, you must have previously set up an account with access and authentication details for the supported LLM model provider you want to use. For example:
|
Choose an implementation
The AI Agent connector is available in two variants, each with different capabilities, suited for different use cases, and available with a dedicated element template:
The right implementation depends on your use case.
| Use case | Implementation | Description |
|---|---|---|
| Agentic workflow with automatic tool calling (most use cases) | AI Agent Sub-process | It handles tool resolution and the feedback loop automatically. No explicit loop modeling is needed. You must include at least one activity/tool inside the sub-process. |
| Inference tasks that don't require tool calling | AI Agent Task without tools | A single, one-shot LLM call with no ad-hoc sub-process. |
| Intercepting tool calls, for example, to add a human approval step or run PII detection before tool execution | AI Agent Task with tools | Tools are provided by an external ad-hoc sub-process that you model explicitly, giving you full control over the feedback loop. This is the most complex configuration. |
The recommended approach for most use cases is to use the AI Agent Sub-process implementation due to the simplified configuration and support for event sub-processes.
Configuration comparison
The following table summarizes the key configuration differences between the two implementations.
| Configuration field | AI Agent Sub-process | AI Agent Task |
|---|---|---|
| Model provider | Yes | Yes |
| Model | Yes | Yes |
| System prompt | Yes | Yes |
| User prompt | Yes | Yes |
| Tools | Automatic (resolved from activities inside the sub-process) | Optional. Requires ad-hoc sub-process ID and tool call results |
| Agent context (memory) | Optional. Only needed when re-entering the agent from an external feedback loop | Required. Must be aligned with the output mapping result variable |
| Limits | Yes | Yes |
| Event handling | Yes | No |
| Response | Yes | Yes |
toolCalls in output | No | Yes. Returned for routing to the ad-hoc sub-process |
| Error handling | Yes | Yes |
| Retries | Yes | Yes |
| Execution listeners | Yes | Yes |
Execution listeners behave differently between the two implementations. On the AI Agent Sub-process, they only run when entering and exiting the ad-hoc sub-process, not on every loop iteration. On the AI Agent Task, they are triggered on every job execution.
AI Agent Sub-process
The AI Agent Sub-process implementation uses the job worker implementation type of an ad-hoc sub-process to provide an integrated solution to handle tool resolution and a feedback loop. This is the recommended implementation type for most use cases, and offers:
- Simplified configuration as the tool feedback loop is handled internally
- Support for handling of event sub-processes within the ad-hoc sub-process
Restrictions
- Because of BPMN semantics, the ad-hoc sub-process must contain at least one activity. This means you cannot create an AI Agent Sub-process without any tools.
- As the tool calling feedback loop is implicitly handled within the AI Agent execution, you have less control over the tool calls.
Example
A basic AI Agent Sub-process might look similar to the following example.
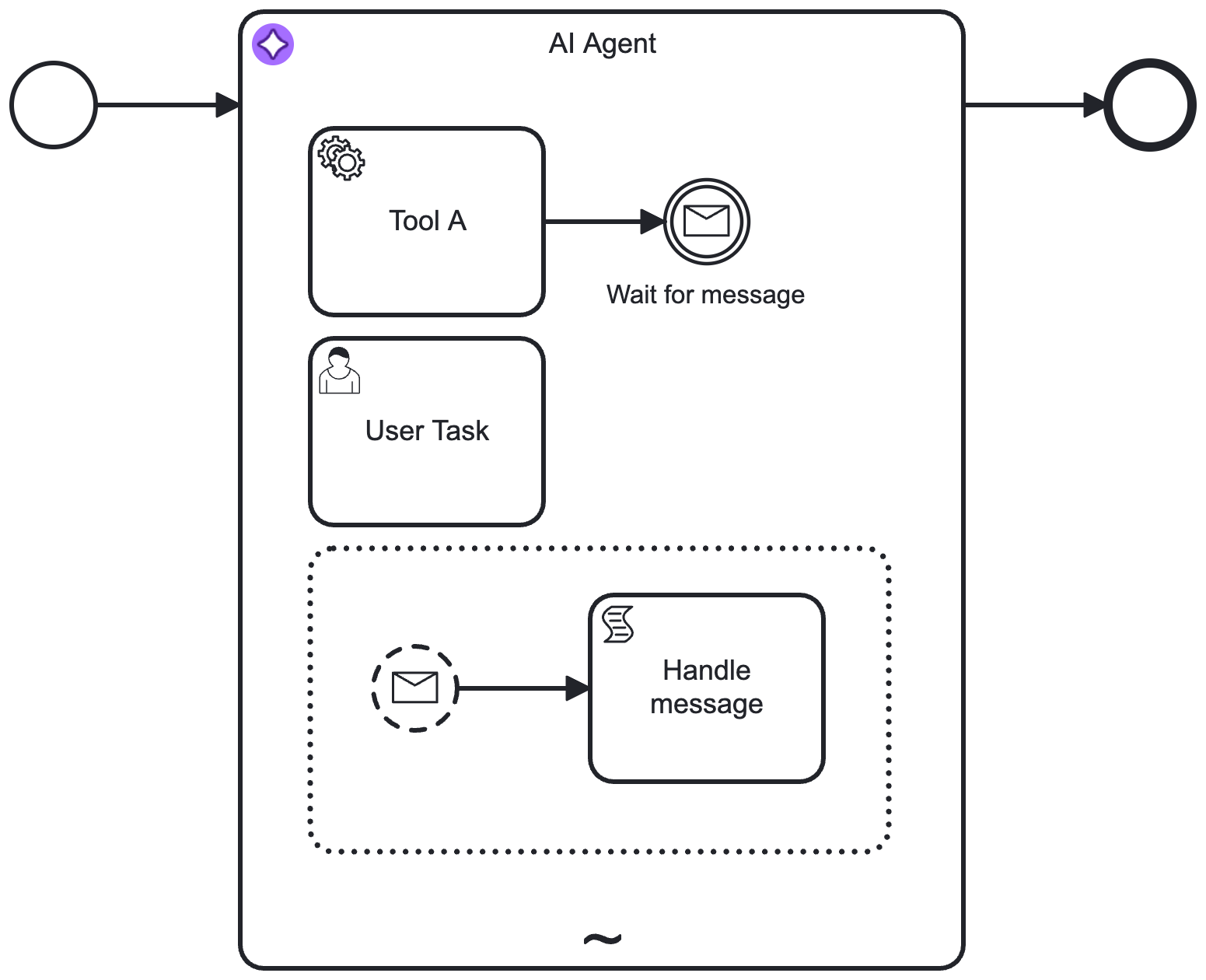
- The connector is configured so the AI Agent resolves available tools and activates them as needed to complete it's goal.
- Handling of event sub-processes within the ad-hoc sub-process is supported (See Event Handling). The AI Agent Task implementation does not support this.
This pattern can also be combined with a user feedback loop for verification or follow-up interactions. For example, instead of the showcased user task, this could also be another LLM acting as a judge, or any other task that validates the agent's response.
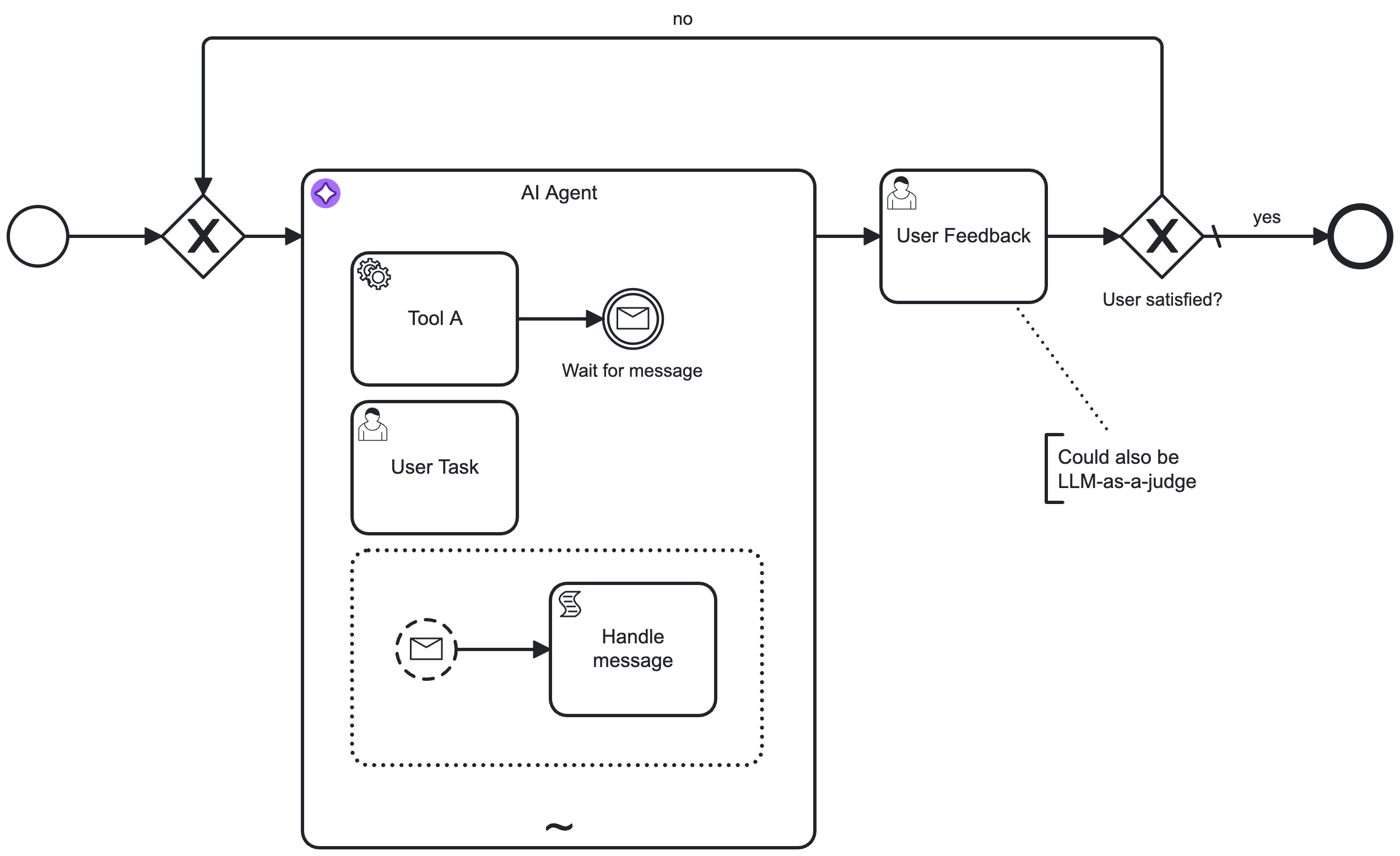
AI Agent Task
The AI Agent Task implementation is the original variant that relies on a BPMN service task in combination with a multi-instance ad-hoc sub-process.
Unlike the AI Agent Sub-process implementation, you must model the feedback loop explicitly in the BPMN diagram, leading to a more complex configuration.
This implementation is best suited for:
- Simple, one-shot tasks using the AI Agent connector as a generic LLM connector without any tool calling.
- Advanced use cases where you want to model the feedback loop explicitly, for example to pre-/post-process tool calls for approval or auditing.
Example
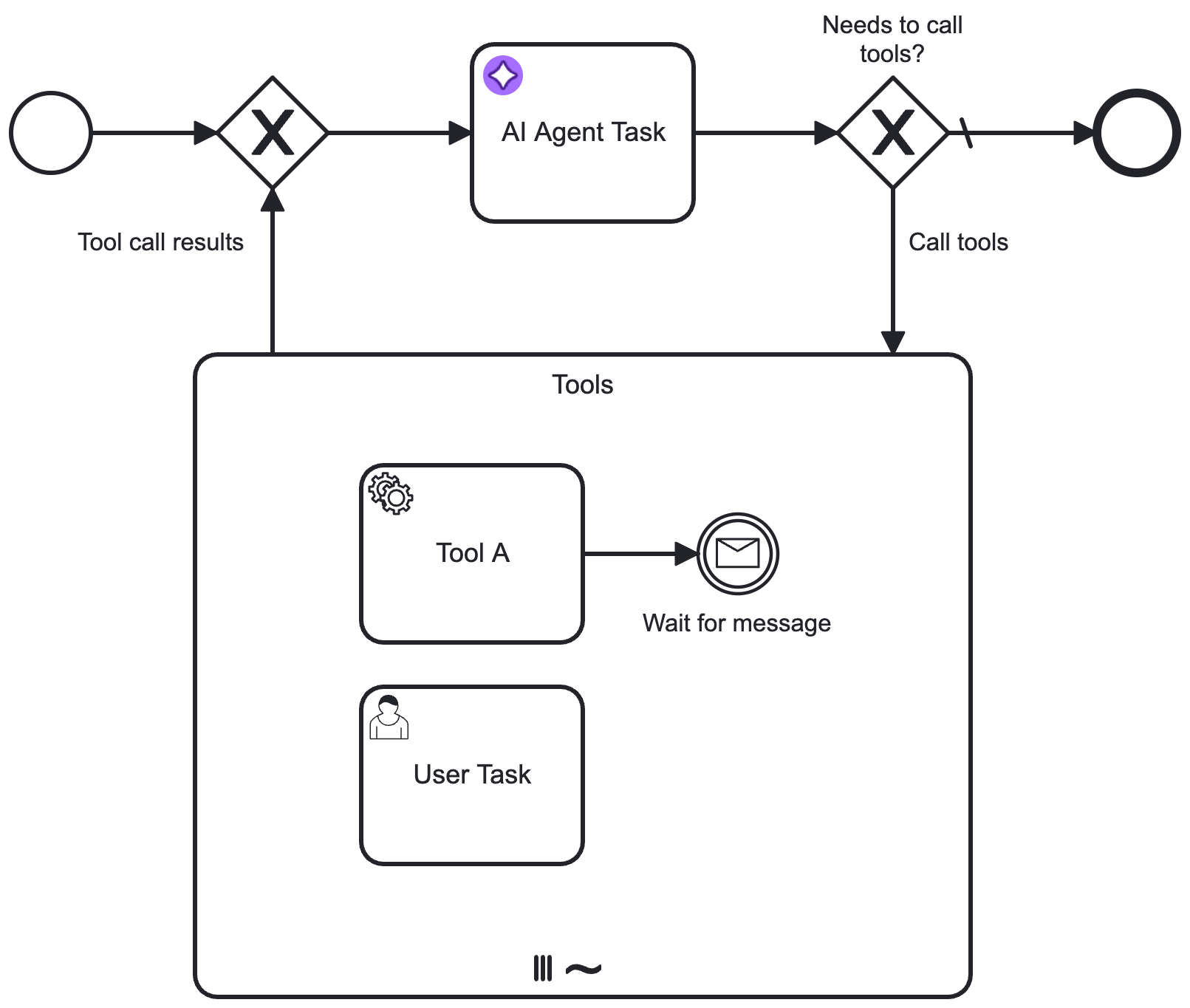
A very simple example of using the AI Agent Task connector for a non-agentic task is as follows:

- The connector can be made agentic by adding a multi-instance ad-hoc sub-process and gateways to create a tool feedback loop.
- The connector will be able to call tools until it reaches its goal or a configured limit.
The multi-instance ad-hoc sub-process acts as a toolbox:
The process can also be further enhanced to add a user feedback loop outside the tool calling loop. When the AI Agent completes its task and does not request any tool calls, its response can be verified with a task (such as a user task or another LLM as a judge), with the process set up to loop back to the AI Agent if required.
This allows you to create a user-in-the-loop process for example, such as a chat where the user can ask follow-up questions:
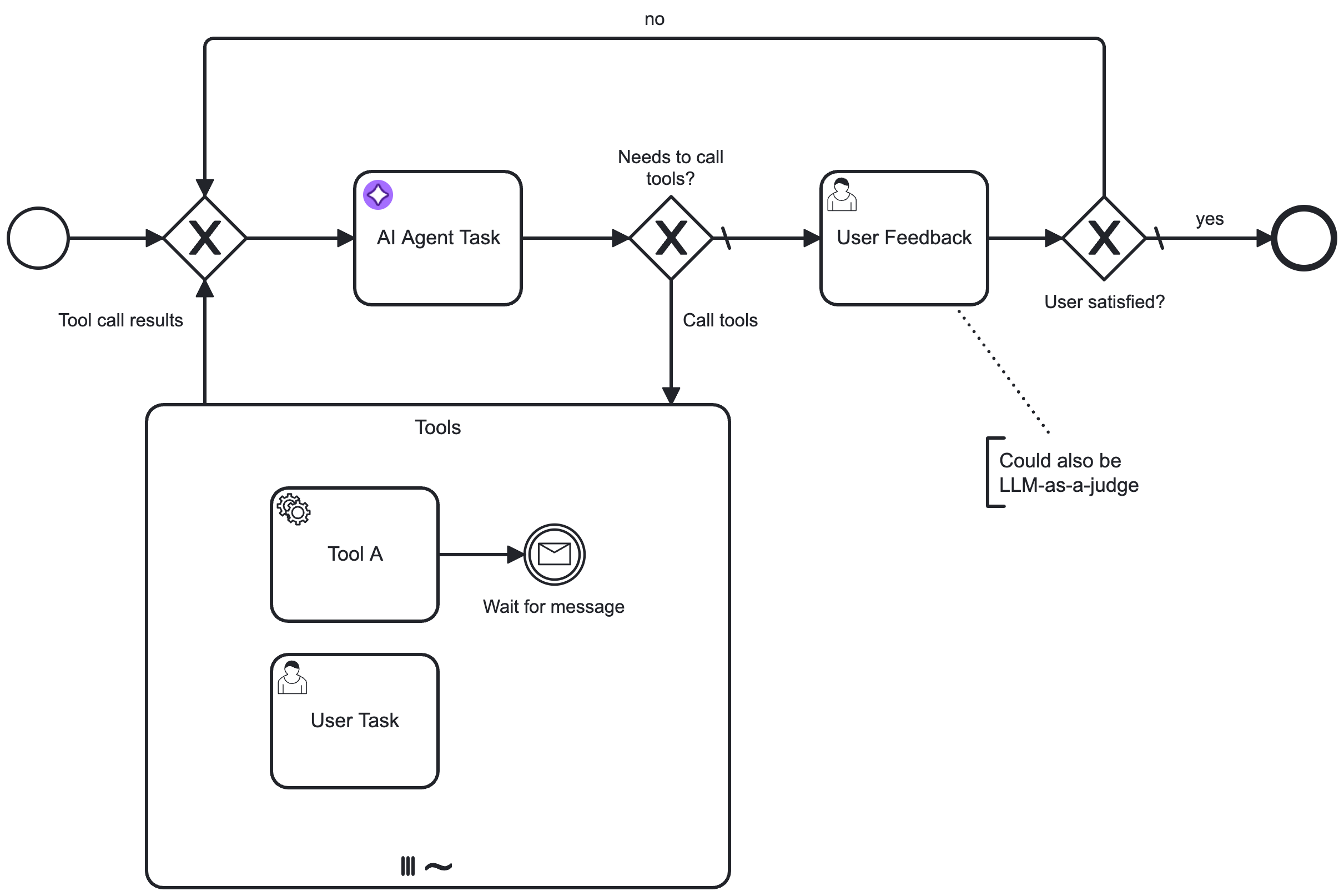
If you need more control over the feedback loop, you can model pre-/post-processing of tool calls with additional tasks, such as approval or tool call auditing.
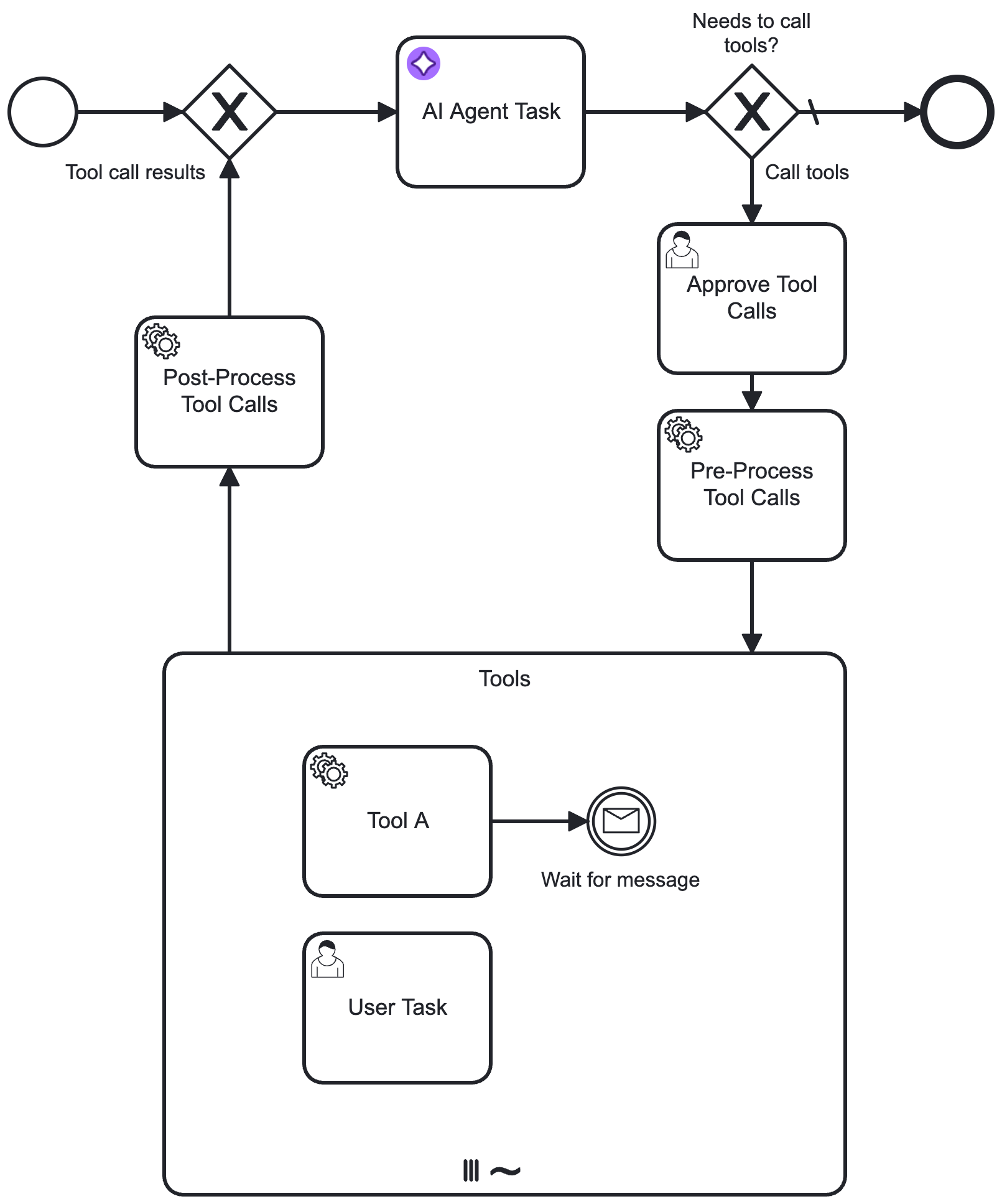
Concepts
System prompt, user prompt, and tool descriptions
Reliable agent behavior depends on three inputs working together:
- System prompt: Defines the agent's role, boundaries, priorities, and success criteria.
- User prompt: Carries the current request and immediate context.
- Tool/task descriptions: Define which actions are available in the ad-hoc sub-process and how each should be used.
At runtime, the connector passes this combined context to the LLM. The model then selects which tools to call (if any), along with parameters.
How task descriptions are used for tools
When using an ad-hoc sub-process, each activity can be exposed as a tool. For best results, document each tool with:
- A clear task name that describes intent.
- A behavior-oriented description that includes when to use it, when not to use it, and the expected outcome.
This makes tool selection more predictable and reduces repeated or incorrect calls.
Execution responsibility split
The decision and execution loop is shared between the LLM and Camunda:
- LLM decides: Which tool to call next, in what order, and with which parameters.
- Camunda orchestrates: Executes the selected BPMN activity, stores variables, applies retries and incident handling, and routes human tasks and events.
This means tools can be called in different orders, repeated, run in parallel, or skipped entirely, while execution remains constrained by the modeled process boundaries.
For a broader overview of how execution works in an AI agent and architectural guidance, see Design and architecture.
Feedback loop
This connector is typically used in a feedback loop, with the connector implementation repeatedly being executed based on tool call results or user feedback until it is able to reach its goal.
For example, the following diagram shows a tool calling loop modeled with the AI Agent Task implementation type.
- The process loops back to the AI Agent connector task from the ad-hoc sub-process until the agent decides no further tool calls are needed.
- With the AI Agent Sub-process implementation type, the tool calling loop is handled internally and so is not explicitly modeled in the BPMN diagram.
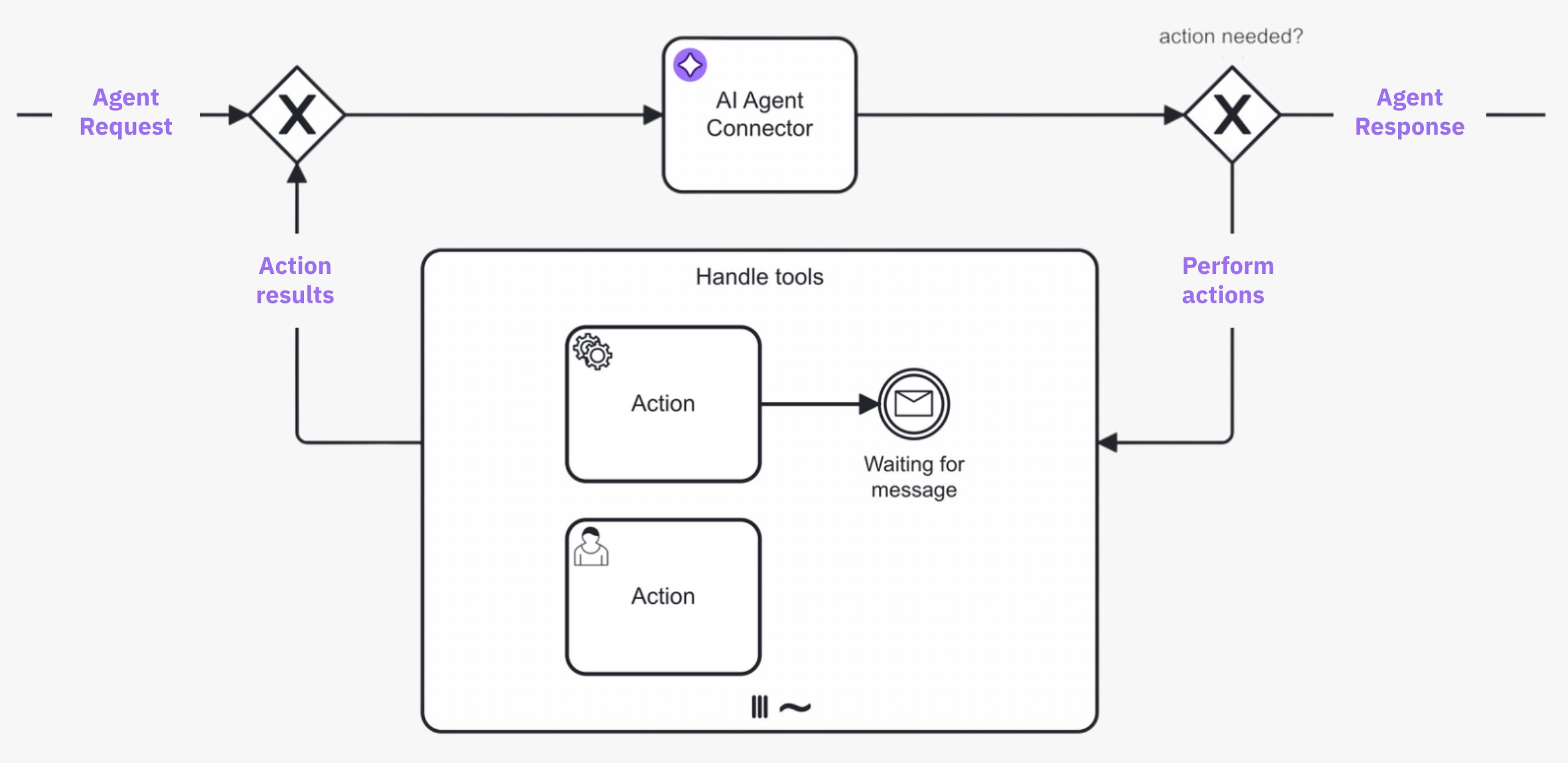
- A request is made to the AI agent connector task, and the LLM determines what action to take.
- If the AI agent decides that further action is needed, the process enters the ad-hoc sub-process and calls any tools deemed necessary to satisfactorily resolve the request.
- The process loops back and re-enters the AI agent connector task, where the LLM decides (with contextual memory) if more action is needed before the process can continue. The process loops repeatedly in this manner until the AI agent decides it is complete, and passes the AI agent response to the next step in the process.
Feedback loop use cases
Typical feedback loop use cases for this connector include the following:
| Use case | Description |
|---|---|
| Tool calling | In combination with an ad-hoc sub-process, the AI Agent connector will resolve available tools and their input parameters, and pass these tool definitions to the LLM.
|
| Response interaction | After returning a response (and without calling any tools), model the process to act upon the response. For example, present the response to a user who can then ask follow-up questions back to the AI Agent connector. |
As the agent preserves the context of the conversation, follow-up questions/tasks and handling of tool call results can relate to the previous interaction with the LLM, allowing the LLM to provide more relevant responses.
Agent context
An important concept to understand is the use of the Agent context process variable to store information required for allowing re-entry to the AI Agent connector task with the same context as before.
Depending on which implementation type is used, the Agent context must be configured differently in the model:
-
AI Agent Sub-process: The agent context is kept within the sub-process scope. This means you only need to configure the agent context when the agent should pick up an existing conversation, for example to model a user feedback loop as in the quickstart example. In this case, you must align the configured agent context variable with the used result variable/expression so that the context update is correctly passed to the next execution of the AI Agent connector task.
-
AI Agent Task: You must align the agent context input variable and the response variable/expression so the context update is correctly passed to the next execution of the AI Agent connector task.
Response format
The AI Agent connector can be configured to instruct the LLM to respond in a structured JSON format, and to parse the JSON structure into a FEEL context accordingly. This allows the LLM to return structured data that can be easily processed in the BPMN process.
Example conversation
The following is a high-level example conversation with the AI Agent connector, including both user and tool feedback loops.
The conversational awareness provided by the agent context allows use cases such as the user only responding with Yes, please proceed, with the agent understanding what it should do next.
# Initial input/user prompt
User: Is John Doe eligible for a credit card?
# Tool feedback loop
AI Agent: Call the `Check_Credit_Card_Eligibility` tool with the following parameters: {"name": "John Doe"}
<process routes through ad-hoc sub-process>
Tool Call Result: {"Check_Credit_Card_Eligibility": {"eligible": true}}
# User feedback loop
AI Agent: John Doe is eligible for a credit card. Would you like to proceed?
<process routes to a user task as no tool calls are requested>
User: Yes, please proceed.
AI Agent: Call the `Create_Credit_Card` tool with the following parameters: {"name": "John Doe"}
Tool Call Result: {"Create_Credit_Card": {"success": true}}
AI Agent: John Doe's credit card has been created successfully.
Process instance migration
Process instance migration is a powerful feature that should be used with caution. Use at your own risk.
Because AI agent implementations are closely tied to the underlying process definition that determines which tools are available, carefully consider the impact of applying process instance migrations to instances using the AI Agent connector while the agent is mid‑conversation. As a result, some migration scenarios are not supported.
Supported migration scenarios
The following migration scenarios are supported for running AI Agent process instances:
| Migration scenario | Description |
|---|---|
| Adding a new tool | Adding a new activity to the ad-hoc sub-process. The new tool is picked up on the next AI Agent execution and added to the agent context. |
| Changing an existing tool without affecting the tool definition | For example, updating a form linked to a user task, or changing a script task implementation. No agent changes are necessary because the tool definition remains unchanged. |
| Changing an existing tool definition | Updating a tool's description or fromAi() parameters is supported, but proceed carefully. See Considerations when changing tool definitions for details. |
| Changing AI Agent configuration (AI Agent Task only) | Updating the system prompt or model parameters on an AI Agent Task. These changes are picked up on the next execution as input mappings are re-evaluated for each loop iteration. This is not supported for the AI Agent Sub-process implementation because the parameters are applied via input mappings to the ad-hoc sub-process which are evaluated only once when entering the sub-process. |
Unsupported migration scenarios
The following migration scenarios are not supported and will result in an error:
| Migration scenario | Description |
|---|---|
| Removing or renaming tools | Removing an existing tool or changing its element ID can lead to stuck executions or validation errors if the agent references tools that no longer exist. The agent throws a MIGRATION_MISSING_TOOLS error when it detects a removed tool. |
| Adding or removing gateway tool definitions (such as MCP or A2A clients) | Gateway tools require a tool discovery flow during initialization. Adding or removing gateway tool definitions to a running agent is not supported as it would require re-executing tool discovery. The agent throws a MIGRATION_GATEWAY_TOOL_DEFINITIONS_CHANGED error when it detects such changes. |
Considerations when changing tool definitions
When you change an existing tool definition (such as updating a tool's description or adding/modifying fromAi() parameters), the AI Agent detects the change and updates its tool definitions on the next execution.
Because a migration can occur between an AI Agent execution and the actual tool call, tools may receive parameters based on the previous definition. Ensure your tool implementations handle this scenario gracefully.
- Description changes: Updates to tool or parameter descriptions take effect on the next AI Agent execution. The LLM uses the updated descriptions when deciding which tools to call.
- Parameter changes: Adding, removing, or modifying
fromAi()parameters is supported. However, the tool implementation must handle potentially missing or changed parameters.
For example:
- A script task should implement a null-check to return an error message if a newly required parameter is missing from an in-flight tool call.
- When changing an input parameter from a numeric type to a complex type (such as an object), the implementation should handle cases where the parameter is still provided using the numeric type.
When a tool receives a parameter in a different format than expected, it can either handle the situation gracefully (for example, by using a default value or converting to a suitable format), or return an actionable error message that can instruct the LLM to provide the correct parameters.
Additional resources
- Intelligent by design: A step-by-step guide to AI task agents in Camunda.
- AI Agent Chat Quick Start blueprint on the Camunda Marketplace.
- Agentic AI examples GitHub repository working examples.
- The MCP Client connector can be used in combination with the AI agent connector to connect to tools exposed by Model Context Protocol (MCP) servers.