Error events
In process automation, you often encounter deviations from the default scenario. One way to resolve these deviations is using a BPMN error event, which allows a process model to react to errors within a task.
For example, if an invalid credit card is used in the process below, the process takes a different path than usual and uses the default payment method to collect money.
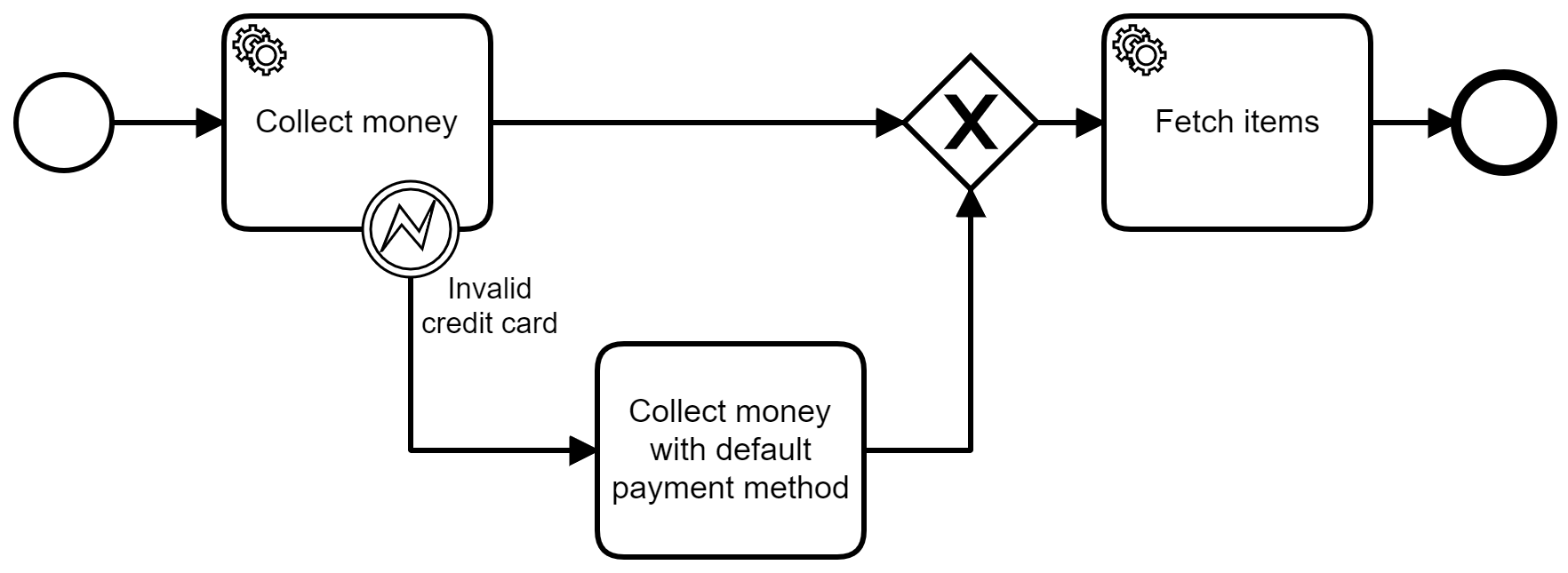
Defining the error
In BPMN, errors define possible errors that can occur. Error events are elements in the process referring to defined errors. An error can be referenced by one or more error events.
An error must define an errorCode. The value of this errorCode is used to determine which catch event can catch the thrown error.
For error throw events, it is possible to define the errorCode as an expression or a static value. If an errorCode expression is configured then it will be evaluated once the event is reached, and used to throw error.
For error catch events errorCode must be a static value.
Alternatively an error catch event may omit the error reference all together. In this case it catches all thrown errors.
Throwing the error
An error can be thrown within the process using an error end event.
Alternatively, you can inform Zeebe that a business error occurred using a client command. This throw error client command can only be used while processing a job.
In addition to throwing the error, this also disables the job and stops it from being activated or completed by other job workers. Refer to the gRPC command and REST request for details.
Catching the error
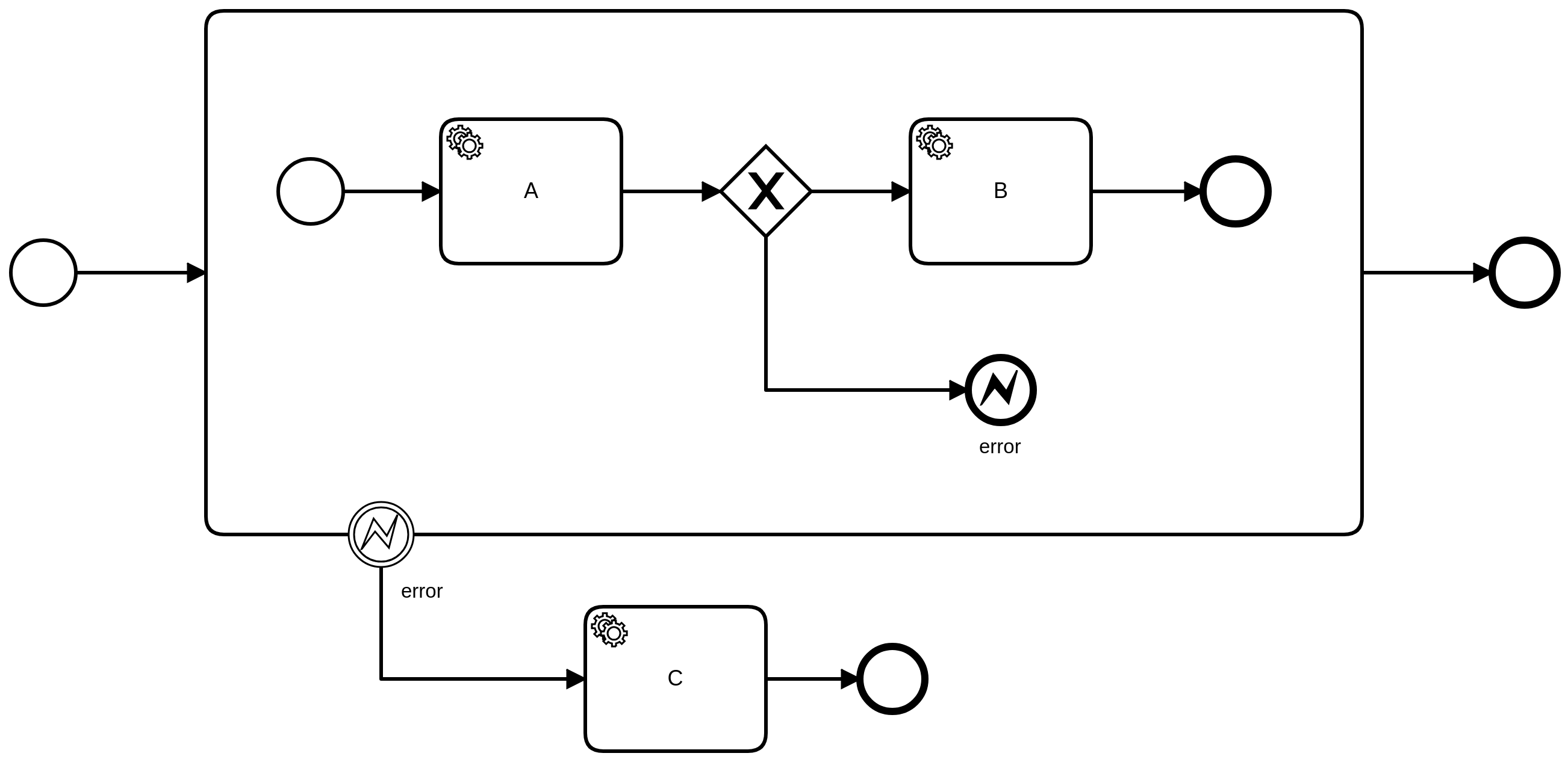
A thrown error can be caught by an error catch event, specifically using an error boundary event or an error event subprocess.
Starting at the scope where the error was thrown, the error code is matched against the attached error boundary events and error event subprocesses at that level. An error is caught by the first event in the scope hierarchy matching the error code. At each scope, the error is either caught, or propagated to the parent scope.
If the process instance is created via call activity, the error can also be caught in the calling parent process instance.
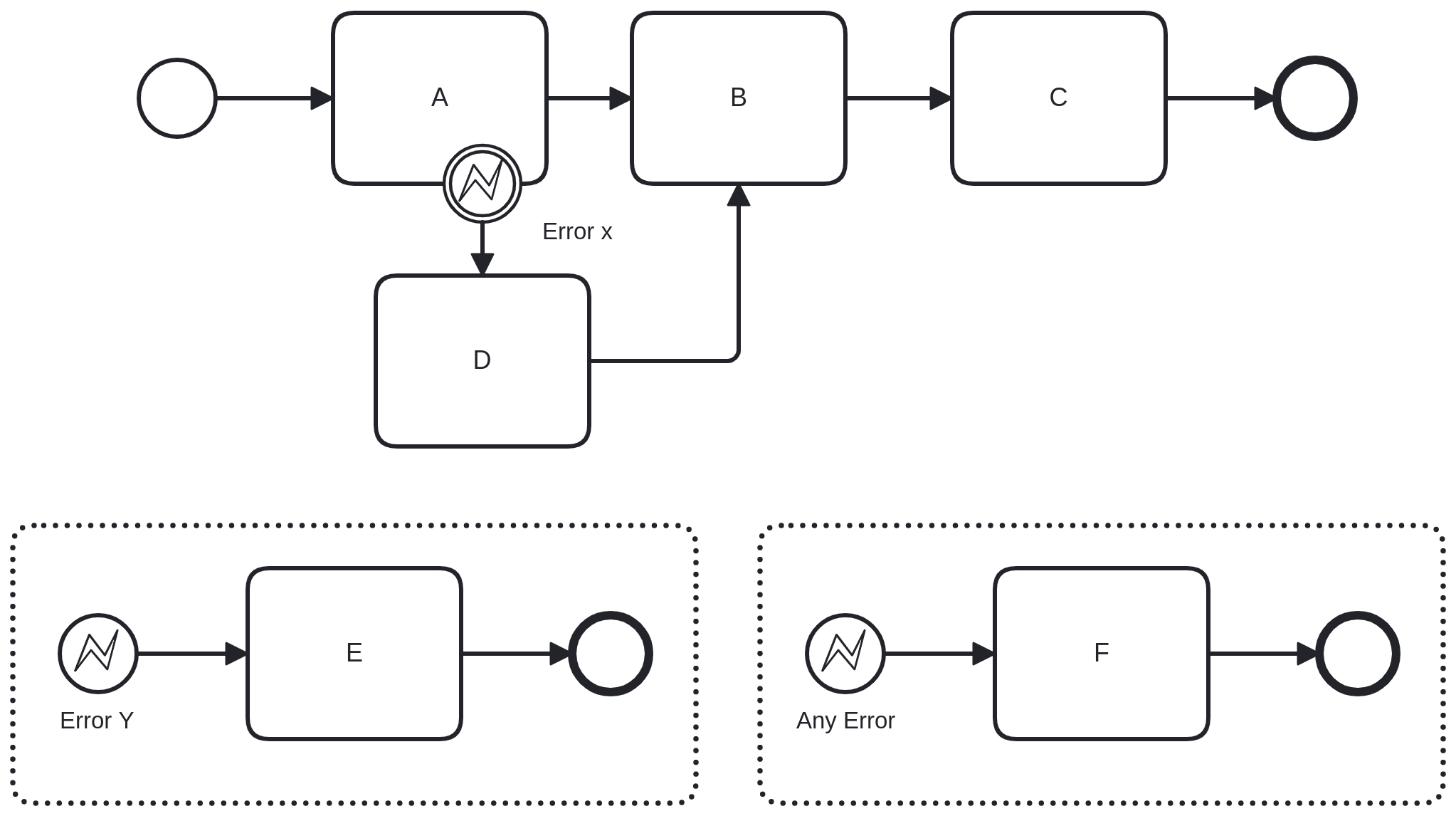
It is not possible to define multiple error catch events with the same errorCode in a single scope. It is also not
permitted to have multiple error catch-all events in a single scope. However, it is possible to define both an error catch event referencing an error with a particular errorCode and an error catch-all event within the same scope. When this happens, the error catch event
that matches the errorCode is prioritized.
Error boundary events and error event subprocesses must be interrupting. This means the process instance will not continue along the regular path, but instead follow the path that leads out of the catching error event.
If the error is thrown for a job, the associated task is terminated first. To continue the execution, the error boundary event or error event subprocess that caught the error is activated.
Unhandled errors
When an error is thrown and not caught, an incident (for example, Unhandled error event) is raised to indicate the failure. The incident is attached to the corresponding element where the error was thrown (that is, the task of the processed job or the error end event).
When you resolve the incident attached to a task, it ignores the error, re-enables the job, and allows it to be activated and completed by a job worker once again.
The incident attached to an error end event cannot be resolved by a user because the failure is in the process itself. The process cannot be changed to catch the error for this process instance.
Business error vs. technical error
In real life, you’ll also have to deal with technical problems that you don't want to treat using error events.
Suppose the credit card service becomes temporarily unavailable. You don't want to model the retrying, as you would have to add it to each and every service task. This will bloat the visual model and confuse business personnel. Instead, either retry or fall back to incidents as described above. This is hidden in the visual.
In this context, we found the terms business error and technical error can be confusing, as they emphasize the source of the error too much. This can lead to long discussions about whether a certain problem is technical or not, and if you are allowed to observe technical errors in a business process model.
It's much more important to look at how you react to certain errors. Even a technical problem can qualify for a business reaction. For example, you could decide to continue a process in the event that a scoring service is not available, and simply give every customer a good rating instead of blocking progress. The error is clearly technical, but the reaction is a business decision.
In general, we recommend talking about business reactions, which are modeled in your process, and technical reactions, which are handled generically using retries or incidents.
Variable mappings
Variables can be passed along into the error catch event with the payload when the error is thrown from the client command. These variables can be merged into the process instance by defining an output mapping at the error catch event.
Visit the documentation regarding variable mappings for more information.
Additional resources
XML representation
A boundary error event:
<bpmn:error id="invalid-credit-card-error" errorCode="Invalid Credit Card" />
<bpmn:boundaryEvent id="invalid-credit-card-1" name="Invalid Credit Card" attachedToRef="collect-money">
<bpmn:errorEventDefinition errorRef="invalid-credit-card-error" />
</bpmn:boundaryEvent>
A error boundary catch-all event:
<bpmn:boundaryEvent id="invalid-credit-card-2" name="Unknown Error" attachedToRef="collect-money">
<bpmn:errorEventDefinition id="catch-all-errors" />
</bpmn:boundaryEvent>